文章目录(Table of Contents)
Batch Normalization工作原理
首先,我们输入的是一个batch,下面的例子中,我们可以将(x1,x2,x3)看成一个Batch。
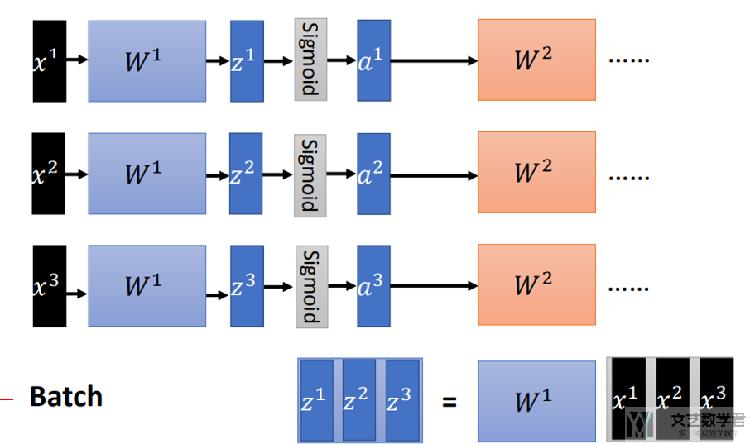
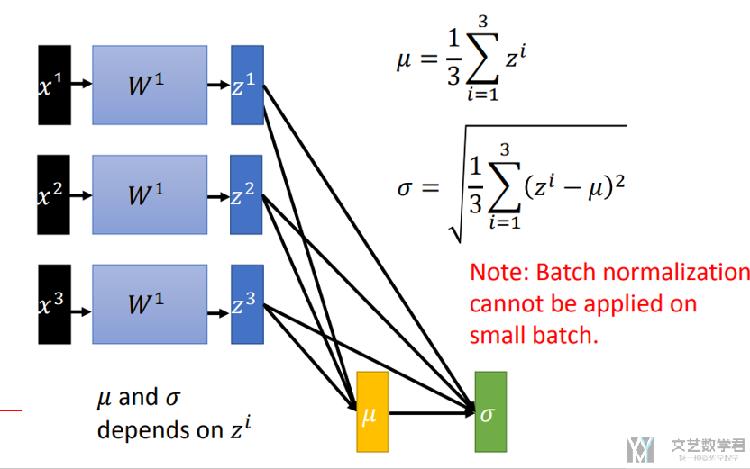
接着,我们计算在经过一层网络后, 输出值(z1,z2,z3)的均值和标准差,如下图所示:
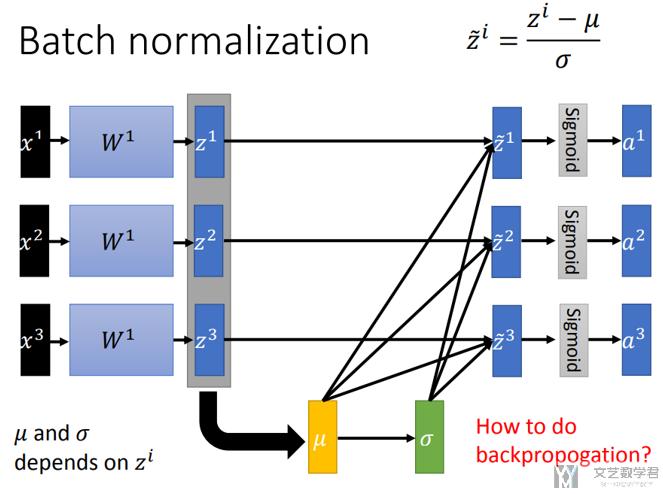
接着,对(z1,z2,z3)进行标准化,标准化后z的均值为0,方差为1;
最后,我们的输出为 z=A*z' + B,其中A和B是需要学习的参数, 这里A和B是包含在Batch Normalization层的参数; 例如我们直接查看Pytorch中BN层的参数, 可以发现是有weight和bias的.
- n = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6))
- n[1].state_dict()
- """
- OrderedDict([('weight', tensor([1., 1., 1., 1., 1., 1.])),
- ('bias', tensor([0., 0., 0., 0., 0., 0.])),
- ('running_mean', tensor([0., 0., 0., 0., 0., 0.])),
- ('running_var', tensor([1., 1., 1., 1., 1., 1.])),
- ('num_batches_tracked', tensor(0))])
- """
我们注意到,当A=标准差, B=均值, 则相当于z_new = z,即相当于没有进行batch normalization.
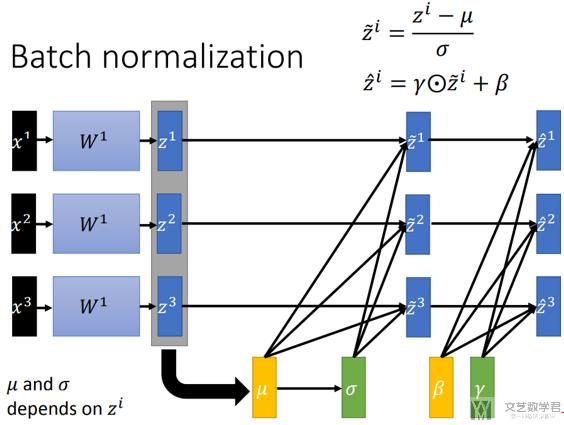
需要注意
- Batch Normalization不能在小数据集上进行,因为均值和方差的估计会不准确。
- 在test上时,不会计算test的均值与方差,会使用trian时候均值方差的移动平均来代替(下面会有一个例子);
Batch Normalization实际使用
在batch normalization的时候,我们在train和test的时候进行的操作是不同的。这是由于在test的时候, 输入数据可能只有一个data, 故不能计算均值和标准差;
所以, 在test的时候, 会使用之前计算得到的均值和标准差做标准化。
初始化参数
首先,我们先初始化一些参数,下面初始化的有我们的测试数据X,测试数据的均值方差,迭代式子里最初的均值方差(均值0,方差1),和迭代的公式。

迭代计算过程
下面看一下在输入是X的情况下,在训练模式下的输出结果和在测试模式下的输出结果。
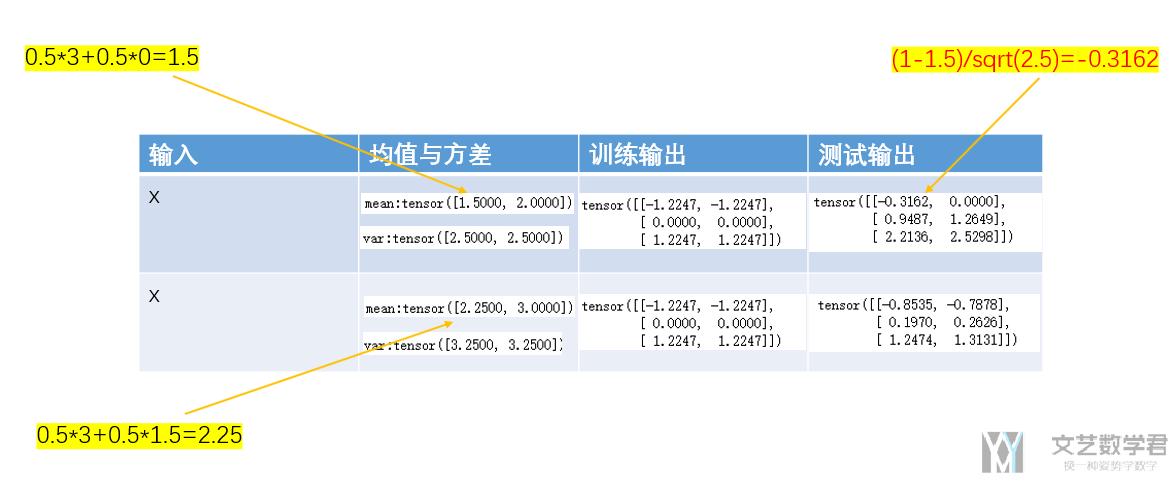
可以看到,在训练模式下,pytorch会对原始数据进行标准化,同时更新均值与方差(这个均值与方差是在test的时候,对test数据进行标准化的)。
在测试模式下,会使用在训练模式下反复计算的均值和方差来进行标准化。具体的计算过程可以结合上面的图进行推导。
第一行是第一次输出X后不同的输出,第二行是第二次输入X后不同的输出。
测试代码
把测试代码放在下面,方便自己测试。
- # Without Learnable Parameters(没有学习参数)
- # 这里是momentum=0.5的情况
- m = nn.BatchNorm1d(2, affine=False, eps=0, momentum=0.5, track_running_stats=True) # 2为输出的特征数
- print("初始化 : {}, :mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- # --------
- # 第一轮
- # --------
- # 训练模式
- m.train()
- output = m(inputData)
- print("TrainModeP : {}, :mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- print("TrainMode:\n{}".format(output))
- # 测试模式
- print('------------')
- m.eval()
- print("EvalMode : {}, mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- output = m(inputData)
- print("EvalMode : {}, mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- print("EvalMode:\n{}".format(output))
- # --------
- # 第二轮
- # --------
- print('\n=====\n')
- # 训练模式
- m.train()
- output = m(inputData)
- print("TrainModeP : {}, :mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- print("TrainMode:\n{}".format(output))
- # 测试模式
- print('------------')
- m.eval()
- print("EvalMode : {}, mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- output = m(inputData)
- print("EvalMode : {}, mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- print("EvalMode:\n{}".format(output))
- # --------
- # 第三轮
- # --------
- print('\n=====\n')
- # 训练模式
- m.train()
- output = m(inputData)
- print("TrainModeP : {}, :mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- print("TrainMode:\n{}".format(output))
- # 测试模式
- print('------------')
- m.eval()
- print("EvalMode : {}, mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- output = m(inputData)
- print("EvalMode : {}, mean:{},var:{}".format(m.training,m.running_mean,m.running_var))
- print("EvalMode:\n{}".format(output))
Batch Normalization的手动实现
为了能够更好的说明Batch Normalization, 我们手动实现一下Batch Norm的功能. 首先是实现计算Batch Norm的函数, 包含:
- moving_mean和moving_var的计算;
- 包含在训练模式和测试模式下对X进行标准化;
- 同时, 这里会有两个参数, 分别是gamma和beta, 是需要在训练的时候进行更新的;
- def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
- # Use torch.is_grad_enabled() to determine whether the current mode is
- # training mode or prediction mode
- if not torch.is_grad_enabled(): # 预测模式就不需要计算均值和方差
- # If it is the prediction mode, directly use the mean and variance
- # obtained from the incoming moving average
- X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
- else:
- assert len(X.shape) in (2, 4) # 长度=2, 全连接; 长度=4, 卷积;
- if len(X.shape) == 2:
- # When using a fully connected layer, calculate the mean and
- # variance on the feature dimension
- mean = X.mean(dim=0)
- var = ((X - mean) ** 2).mean(dim=0)
- else:
- # When using a two-dimensional convolutional layer, calculate the
- # mean and variance on the channel dimension (axis=1). Here we
- # need to maintain the shape of `X`, so that the broadcast
- # operation can be carried out later
- mean = X.mean(dim=(0, 2, 3), keepdim=True)
- var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
- # In training mode, the current mean and variance are used for the
- # standardization
- X_hat = (X - mean) / torch.sqrt(var + eps)
- # Update the mean and variance of the moving average
- moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
- moving_var = momentum * moving_var + (1.0 - momentum) * var
- Y = gamma * X_hat + beta # Scale and shift
- return Y, moving_mean, moving_var
定义了上面计算的函数之后, 下面就是定义BatchNorm layer. 这里会存储moving_mean和moving_var, 会存储参数gamma和beta.
- class BatchNorm(nn.Module):
- # num_features: the number of outputs for a fully-connected layer
- # or the number of output channels for a convolutional layer.
- # num_dims: 2 for a fully-connected layer and 4 for a convolutional layer.
- def __init__(self, num_features, num_dims):
- super().__init__()
- if num_dims == 2:
- shape = (1, num_features)
- else:
- shape = (1, num_features, 1, 1)
- # The scale parameter and the shift parameter involved in gradient
- # finding and iteration are initialized to 0 and 1 respectively
- self.gamma = nn.Parameter(torch.ones(shape))
- self.beta = nn.Parameter(torch.zeros(shape))
- # All the variables not involved in gradient finding and iteration are
- # initialized to 0 on the CPU
- self.moving_mean = torch.zeros(shape)
- self.moving_var = torch.zeros(shape)
- def forward(self, X):
- # If X is not on the CPU, copy `moving_mean` and `moving_var` to the
- # device where `X` is located
- if self.moving_mean.device != X.device:
- self.moving_mean = self.moving_mean.to(X.device)
- self.moving_var = self.moving_var.to(X.device)
- # Save the updated `moving_mean` and `moving_var`
- Y, self.moving_mean, self.moving_var = batch_norm(
- X, self.gamma, self.beta, self.moving_mean,
- self.moving_var, eps=1e-5, momentum=0.9)
- return Y
上面计算过程与实际的layer分开的过程, 是非常好的. (This pattern enables a clean separation of math from boilerplate code.)
直接使用Pytorch中的BatchNorm
上面我们自己动手实现了BatchNorm的相关操作, 但是在实际情况中, 我们会直接使用框架中现成的函数, 这样使用起来就会方便很多. 下面我们将LeNet加上BatchNorm, 注意我们在全连接层的部分也是可以增加一维的BatchNorm的, 整体的代码如下所示:
- net = nn.Sequential(
- nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
- nn.MaxPool2d(kernel_size=2, stride=2), nn.Flatten(),
- nn.Linear(7056, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
- nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
- nn.Linear(84, 10))
Batch Normalization实验
之前在dropout的实验里,我们可以看到使用dropout后,准确率变化如下所示:
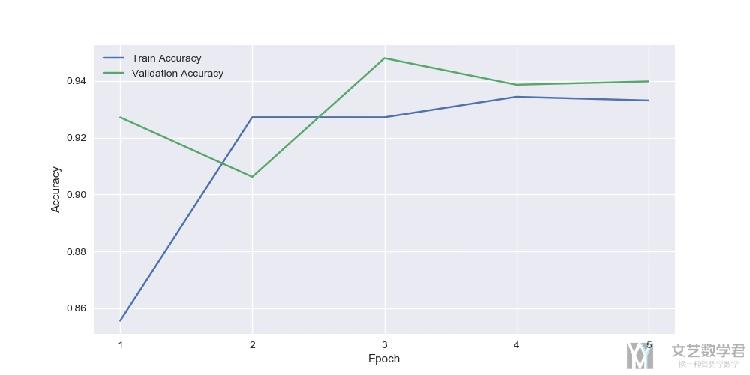
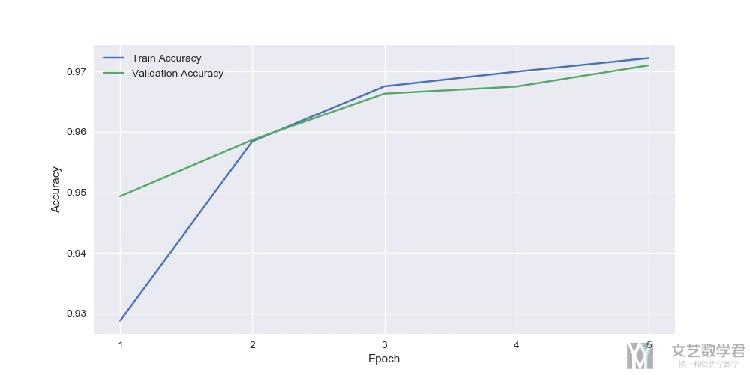
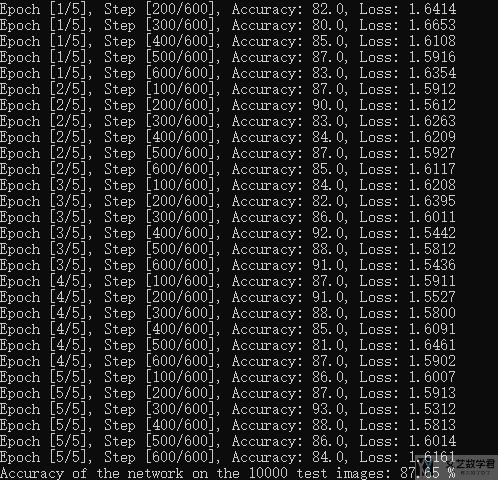
在使用batch normalization后,我们可以看到准确率有了进一步的提升:
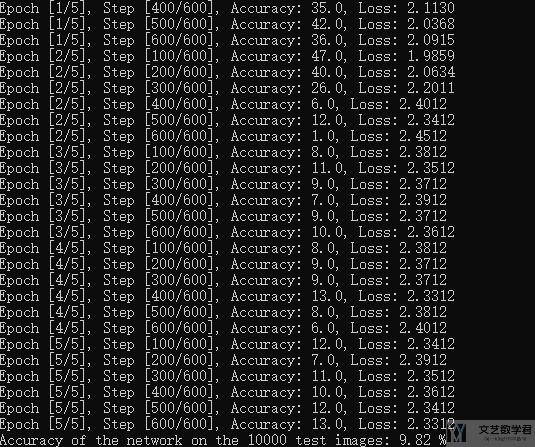
原始模型train不起来
我们看一下原始模型训练不起来的情况,如下图所示,在训练集上准确率只有10%左右
在使用batch normalization后,模型在训练集上的准确率可以提升到80%以上;
结语
数据标准化是很重要的一步,会对模型最终的好坏起到至关重要的作用。Batch Normalization在model无法train起来的时候,也就是在训练集上结果很差的时候,会起到比较好的作用。

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论