文章目录(Table of Contents)
简单原理
其实这个的原理和CNN可视化Convolutional Features很相似,简单来说,要看某个filter在检测什么,我们让通过其后的输出激活值较大。想要一些样本,有一个简单的想法就是让最后结果中是某一类的概率值变大,接着进行反向传播(固定住网络的参数),去修改input. 下面有一个简单的图示:
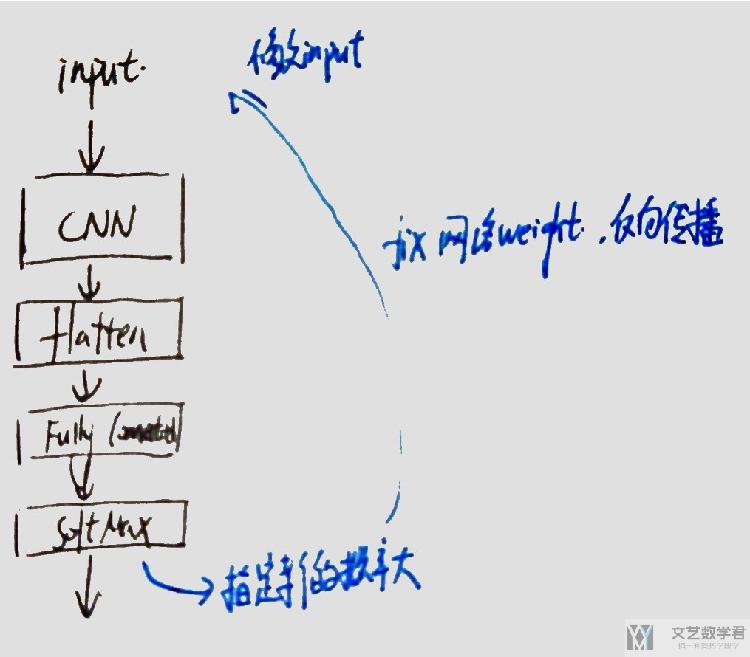
下面看一下具体的实验.
具体实现
训练一个分类网络
下面的方法是一套比较通用的写法,训练别的网络的时候也是可以加以参考的。
首先我们训练一个CNN网络,可以用于手写数字的分类。首先导入需要使用的库。
- import time
- import csv, os
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import cv2
- from cv2 import resize
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- from torch.utils.data.sampler import SubsetRandomSampler
- from torch.autograd import Variable
- import torch.utils.data as Data
- from sklearn import preprocessing
- import copycopy
- import torchvision
- import torchvision.transforms as transforms
接着定义绘制loss图像的函数。
- # ---------------
- # Visual The Loss
- # ---------------
- def draw_loss_acc(train_list,validation_list,mode='Loss'):
- plt.style.use('seaborn')
- fig = plt.figure(figsize=(10,5))
- ax = fig.add_subplot(1, 1, 1)
- # 设置间隔
- data_len = len(train_list)
- x_ticks = np.arange(1,data_len+1)
- plt.xticks(x_ticks)
- if mode == 'Loss':
- plt.plot(x_ticks,train_list,label='Train Loss')
- plt.plot(x_ticks,validation_list,label='Validation Loss')
- plt.xlabel('Epoch')
- plt.ylabel('Loss')
- plt.legend()
- plt.savefig('Epoch_loss.jpg')
- elif mode == 'Accuracy':
- plt.plot(x_ticks,train_list,label='Train Accuracy')
- plt.plot(x_ticks,validation_list,label='Validation Accuracy')
- plt.xlabel('Epoch')
- plt.ylabel('Accuracy')
- plt.legend()
- plt.savefig('Epoch_Accuracy.jpg')
接着定义训练时需要使用的函数。
- # ----------------
- # Train the model
- # ----------------
- def train_model(model, criterion, optimizer, dataloaders, train_datalengths, scheduler=None, num_epochs=2):
- """传入的参数分别是:
- 1. model:定义的模型结构
- 2. criterion:损失函数
- 3. optimizer:优化器
- 4. dataloaders:training dataset
- 5. train_datalengths:train set和validation set的大小, 为了计算准确率
- 6. scheduler:lr的更新策略
- 7. num_epochs:训练的epochs
- """
- since = time.time()
- # 保存最好一次的模型参数和最好的准确率
- best_model_wts = copycopy.deepcopy(model.state_dict())
- best_acc = 0.0
- train_loss = [] # 记录每一个epoch后的train的loss
- train_acc = []
- validation_loss = []
- validation_acc = []
- for epoch in range(num_epochs):
- print('Epoch [{}/{}]'.format(epoch+1, num_epochs))
- print('-' * 10)
- # Each epoch has a training and validation phase
- for phase in ['train', 'val']:
- if phase == 'train':
- if scheduler != None:
- scheduler.step()
- model.train() # Set model to training mode
- else:
- model.eval() # Set model to evaluate mode
- running_loss = 0.0 # 这个是一个epoch积累一次
- running_corrects = 0 # 这个是一个epoch积累一次
- # Iterate over data.
- total_step = len(dataloaders[phase])
- for i, (inputs, labels) in enumerate(dataloaders[phase]):
- # inputs = inputs.reshape(-1, 28*28).to(device)
- inputs = inputs.to(device)
- labels = labels.to(device)
- # zero the parameter gradients
- optimizer.zero_grad()
- # forward
- # track history if only in train
- with torch.set_grad_enabled(phase == 'train'):
- outputs = model(inputs)
- _, preds = torch.max(outputs, 1) # 使用output(概率)得到预测
- loss = criterion(outputs, labels) # 使用output计算误差
- # backward + optimize only if in training phase
- if phase == 'train':
- loss.backward()
- optimizer.step()
- # statistics
- running_loss += loss.item() * inputs.size(0)
- running_corrects += torch.sum(preds == labels.data)
- if (i+1)%100==0:
- # 这里相当于是i*batch_size的样本个数打印一次, i*100
- iteration_loss = loss.item()/inputs.size(0)
- iteration_acc = 100*torch.sum(preds == labels.data).item() / len(preds)
- print ('Mode {}, Epoch [{}/{}], Step [{}/{}], Accuracy: {}, Loss: {:.4f}'.format(phase, epoch+1, num_epochs, i+1, total_step, iteration_acc, iteration_loss))
- epoch_loss = running_loss / train_datalengths[phase]
- epoch_acc = running_corrects.double() / train_datalengths[phase]
- if phase == 'train':
- train_loss.append(epoch_loss)
- train_acc.append(epoch_acc)
- else:
- validation_loss.append(epoch_loss)
- validation_acc.append(epoch_acc)
- print('*'*10)
- print('Mode: [{}], Loss: {:.4f}, Acc: {:.4f}'.format(
- phase, epoch_loss, epoch_acc))
- print('*'*10)
- # deep copy the model
- if phase == 'val' and epoch_acc > best_acc:
- best_acc = epoch_acc
- best_model_wts = copycopy.deepcopy(model.state_dict())
- print()
- time_elapsed = time.time() - since
- print('*'*10)
- print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
- print('Best val Acc: {:4f}'.format(best_acc))
- print('*'*10)
- # load best model weights
- final_model = copycopy.deepcopy(model) # 最后得到的model
- model.load_state_dict(best_model_wts) # 在验证集上最好的model
- draw_loss_acc(train_list=train_loss,validation_list=validation_loss,mode='Loss') # 绘制Loss图像
- draw_loss_acc(train_list=train_acc,validation_list=validation_acc,mode='Accuracy') # 绘制准确率图像
- return (model,final_model)
定义全局变量,learning_rate与num_epochs等.
- # --------------------
- # Device configuration
- # --------------------
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- # ----------------
- # Hyper-parameters
- # ----------------
- num_classes = 10
- num_epochs = 3
- batch_size = 100
- validation_split = 0.05 # 每次训练集中选出10%作为
- learning_rate = 0.001
接着我们进行加载数据.
- # -------------
- # MNIST dataset
- # -------------
- train_dataset = torchvision.datasets.MNIST(root='./',
- train=True,
- transform=transforms.ToTensor(),
- download=True)
- test_dataset = torchvision.datasets.MNIST(root='./',
- train=False,
- transform=transforms.ToTensor())
- # -----------
- # Data loader
- # -----------
- test_len = len(test_dataset) # 计算测试集的个数
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=False)
- for (inputs,labels) in test_loader:
- print(inputs.size())
- print(labels.size())
- break
- # ------------------
- # 下面切分validation
- # ------------------
- dataset_len = len(train_dataset)
- indices = list(range(dataset_len))
- # Randomly splitting indices:
- val_len = int(np.floor(validation_split * dataset_len)) # validation的长度
- validation_idx = np.random.choice(indices, size=val_len, replace=False) # validatiuon的index
- train_idx = list(set(indices) - set(validation_idx)) # train的index
- ## Defining the samplers for each phase based on the random indices:
- train_sampler = SubsetRandomSampler(train_idx)
- validation_sampler = SubsetRandomSampler(validation_idx)
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- sampler=train_sampler,
- batch_size=batch_size)
- validation_loader = torch.utils.data.DataLoader(train_dataset,
- sampler=validation_sampler,
- batch_size=batch_size)
- train_dataloaders = {"train": train_loader, "val": validation_loader} # 使用字典的方式进行保存
- train_datalengths = {"train": len(train_idx), "val": val_len} # 保存train和validation的长度
模型的定义与模型的初始化.
- # -------------------------------------------------------
- # Convolutional neural network (two convolutional layers)
- # -------------------------------------------------------
- class ConvNet(nn.Module):
- def __init__(self, num_classes=10):
- super(ConvNet, self).__init__()
- self.layer1 = nn.Sequential(
- nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2),
- nn.BatchNorm2d(16),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=2, stride=2))
- self.layer2 = nn.Sequential(
- nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2),
- nn.BatchNorm2d(32),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=2, stride=2))
- self.fc = nn.Linear(7*7*32, num_classes)
- def forward(self, x):
- out = self.layer1(x)
- out = self.layer2(out)
- out = out.reshape(out.size(0), -1)
- out = self.fc(out)
- return out
- # 模型初始化
- model = ConvNet(num_classes=num_classes).to(device)
定义损失函数与优化器,进行训练
- # -------------------
- # Loss and optimizer
- # ------------------
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
- # -------------
- # 进行模型的训练
- # -------------
- (best_model,final_model) = train_model(model=model,criterion=criterion,optimizer=optimizer,dataloaders=train_dataloaders,train_datalengths=train_datalengths,num_epochs=num_epochs)
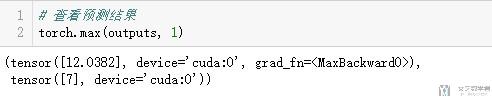
我们测试一下模型的效果。选取test中的第一个数据,为7.

接着带入模型进行预测,查看模型的结果。
- # 带入模型进行预测
- inputdata = test_dataset.data[0].view(1,1,28,28).float()/255
- inputdata = inputdata.to(device)
- outputs = model(inputdata)
- outputs

- # 查看预测结果
- torch.max(outputs, 1)
控制输出的概率, 看输出是什么
这里我们希望做的是:
- 初始随机一张图片
- 我们希望让分类中某个数的概率最大
- 最后看一下这个网络认为什么样的图像是这个数字
所以最终的步骤大概如下所示:
- 初始化一张图片, 28*28
- 使用上面训练好的网络,固定网络参数;
- 最后一层因为是10个输出(相当于是概率), 我们loss设置为某个的负的概率值
- 梯度下降, 使负的概率下降,即相对应的概率值上升,我们最终修改的是初始的图片
- # hook住模型
- layer = 2
- activations = SaveFeatures(list(model.children())[layer])
- # 超参数
- lr = 0.05 # 学习率
- opt_steps = 100 # 迭代次数
- upscaling_factor = 10 # 放大的倍数(为了最后图像的保存)
- # 保存迭代后的数字
- true_nums = []
- # 带入网络进行迭代
- for true_num in range(0,10):
- # 初始化随机图片(数据定义和优化器一定要在一起)
- # 定义数据
- sz = 28
- img = np.uint8(np.random.uniform(0, 255, (1, sz, sz)))/255
- img = torch.from_numpy(img[None]).float().to(device)
- img_var = Variable(img, requires_grad=True)
- # 定义优化器
- optimizer = torch.optim.Adam([img_var], lr=lr, weight_decay=1e-6)
- for n in range(opt_steps): # optimize pixel values for opt_steps times
- optimizer.zero_grad()
- model(img_var) # 正向传播
- loss = -(activations.features[0, true_num]-activations.features[0].mean()) # loss相当于最大该层的激活的值
- # loss = -activations.features[0, true_num]
- loss.backward()
- optimizer.step()
- # 打印最后的img的样子
- print(activations.features[0, true_num])
- print(activations.features[0])
- print('========')
- img = img_var.cpu().clone()
- img = img.squeeze(0)
- # 图像的裁剪(确保像素值的范围)
- img=1
- img=0
- true_nums.append(img)
- unloader = transforms.ToPILImage()
- img = unloader(img)
- img = cv2.cvtColor(np.asarray(img),cv2.COLOR_RGB2BGR)
- sz = int(upscaling_factor * sz) # calculate new image size
- img = cv2.resize(img, (sz, sz), interpolation = cv2.INTER_CUBIC) # scale image up
- cv2.imwrite('num_{}.jpg'.format(true_num),img)
- # 移除hook
- activations.close()
我们看最后输出的两个的效果,分别如下所示。

我们将生成的图片,重新放回进行预测,查看预测的结果:

可以看到,除了第一个数字0会预测错误,其他都是能正确分类。关于第一个分类错误的原因,是由于我们进行了像素的裁剪(小于0的等于0,大于1的等于1)
让正确的图片分类错误
这里的步骤基本是和上面相同的,除了初始化的步骤不相同。上面使用随机图片进行初始化,这里使用特定数字的图片进行初始化。
- 使用特定数字的图片,如数字7(初始化方式与前面的不一样)
- 使用上面训练好的网络,固定网络参数;
- 最后一层因为是10个输出(相当于是概率), 我们loss设置为某个的负的概率值
- 梯度下降, 使负的概率下降,即相对应的概率值上升,我们最终修改的是初始的图片
- 这样使得网络认为这张图片识别的数字的概率增加
- # hook住模型
- layer = 2
- activations = SaveFeatures(list(model.children())[layer])
- # 超参数
- lr = 0.005 # 学习率
- opt_steps = 70 # 迭代次数
- upscaling_factor = 10 # 放大的倍数(为了最后图像的保存)
- # 保存迭代后的数字
- true_nums = []
- # 带入网络进行迭代
- for true_num in range(0,10):
- # 初始化随机图片(数据定义和优化器一定要在一起)
- # 定义数据
- sz = 28
- # 将7变成0,1,2,3,4,5,6,7,8,9
- img = test_dataset.data[0].view(1,1,28,28).float()/255
- img = img.to(device)
- img_var = Variable(img, requires_grad=True)
- # 定义优化器
- optimizer = torch.optim.Adam([img_var], lr=lr, weight_decay=1e-6)
- for n in range(opt_steps): # optimize pixel values for opt_steps times
- optimizer.zero_grad()
- model(img_var) # 正向传播
- # 这里的loss确保某个值的输出大, 并且与原图不会相差很多
- loss = -activations.features[0, true_num] + F.mse_loss(img_var,img)
- loss.backward()
- optimizer.step()
- # 打印最后的img的样子
- print(activations.features[0, true_num])
- print(activations.features[0])
- print('========')
- img = img_var.cpu().clone()
- img = img.squeeze(0)
- # 图像的裁剪(确保像素值的范围)
- img=1
- img=0
- true_nums.append(img)
- unloader = transforms.ToPILImage()
- img = unloader(img)
- img = cv2.cvtColor(np.asarray(img),cv2.COLOR_RGB2BGR)
- sz = int(upscaling_factor * sz) # calculate new image size
- img = cv2.resize(img, (sz, sz), interpolation = cv2.INTER_CUBIC) # scale image up
- cv2.imwrite('real7_regonize{}.jpg'.format(true_num),img)
- # 移除hook
- activations.close()
我们看一下最终的效果,最终会在原始的7的图片上进行修改,得到下面的图片,使得网络分类错误。

其实大致的思想都是类似的,都是固定网络参数,希望输出的某个概率最大,于是进行反向传播,更改输入的值,达到想要的效果。
代码仓库 : MNIST攻击样本
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论