文章目录(Table of Contents)
简介
这里主要简单介绍一下使用Pytorch实现一个简单的RNN来做MNIST的手写数字的识别。主要参考文章链接 : Building RNNs is Fun with PyTorch and Google Colab
直接使用原文的话来介绍这个:
Let's try to build an image classifier using the MNIST dataset. The MNIST dataset consists of images that contain hand-written numbers from 1–10. Essentially, we want to build a classifier to predict the numbers displayed by a set of images. I know this sounds strange but you will be surprised by how well RNNs perform on this image classification task.
大概原理
我们将一张图片看成一个序列,如MNIST中28行看成28个序列, 每个序列有28个特征(如下图所示).
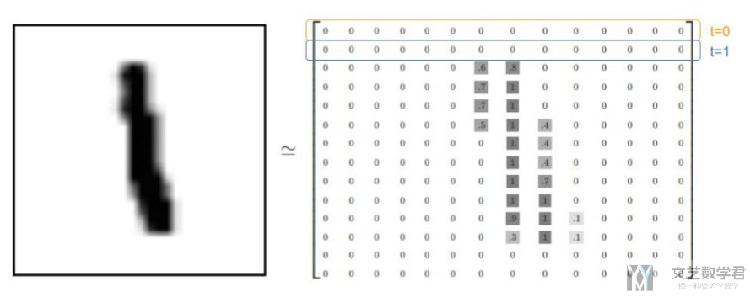
使用最后一次的output, 后接全连接层, 用来做分类, 整体的框架如下图所示;
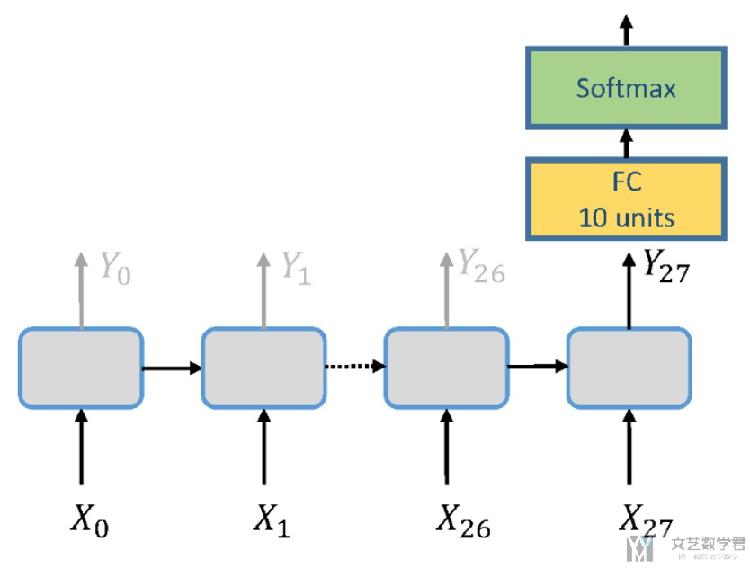
可以注意到上图中输入的为x_0到x_27, 相当于依次输入图像的28行.
一个小技巧
我们在初始化网络的W_hh的时候,初始化为对角矩阵。在后面详细实现的地方还会有提到。在这里强调一下。
详细实现
导入需要使用的库
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- import torchvision
- import torchvision.transforms as transforms
- import numpy as np
- import matplotlib.pyplot as plt
导入数据集
- # -------------
- # MNIST dataset
- # -------------
- batch_size = 128
- train_dataset = torchvision.datasets.MNIST(root='./',
- train=True,
- transform=transforms.ToTensor(),
- download=True)
- test_dataset = torchvision.datasets.MNIST(root='./',
- train=False,
- transform=transforms.ToTensor())
- # Data loader
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=batch_size,
- shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=False)
我们查看一下数据集中的数据。
- # ---------------------
- # Exploring the dataset
- # ---------------------
- # function to sbow an image
- def imshow(img):
- npimg = img.numpy()
- plt.imshow(np.transpose(npimg,(1,2,0)))
- # get some random training images
- dataiter = iter(train_loader)
- images,labels = dataiter.next()
- # show image
- imshow(torchvision.utils.make_grid(images,nrow=15))

定义模型
- # ----------
- # parameters
- # ----------
- N_STEPS = 28
- N_INPUTS = 28 # 输入数据的维度
- N_NEURONS = 150 # RNN中间的特征的大小
- N_OUTPUT = 10 # 输出数据的维度(分类的个数)
- N_EPHOCS = 10 # epoch的大小
- N_LAYERS = 3
- # ------
- # models
- # ------
- class ImageRNN(nn.Module):
- def __init__(self, batch_size, n_inputs, n_neurons, n_outputs, n_layers):
- super(ImageRNN, self).__init__()
- self.batch_size = batch_size # 输入的时候batch_size
- self.n_inputs = n_inputs # 输入的维度
- self.n_outputs = n_outputs # 分类的大小
- self.n_neurons = n_neurons # RNN中输出的维度
- self.n_layers = n_layers # RNN中的层数
- self.basic_rnn = nn.RNN(self.n_inputs, self.n_neurons, num_layers=self.n_layers)
- self.FC = nn.Linear(self.n_neurons, self.n_outputs)
- def init_hidden(self):
- # (num_layers, batch_size, n_neurons)
- # initialize hidden weights with zero values
- # 这个是net的memory, 初始化memory为0
- return (torch.zeros(self.n_layers, self.batch_size, self.n_neurons).to(device))
- def forward(self,x):
- # transforms x to dimensions : n_step × batch_size × n_inputs
- x = x.permute(1,0,2) # 需要把n_step放在第一个
- self.batch_size = x.size(1) # 每次需要重新计算batch_size, 因为可能会出现不能完整方下一个batch的情况
- self.hidden = self.init_hidden() # 初始化hidden state
- rnn_out, self.hidden = self.basic_rnn(x,self.hidden) # 前向传播
- out = self.FC(rnn_out[-1]) # 求出每一类的概率
- return out.view(-1,self.n_outputs) # 最终输出大小 : batch_size X n_output
这里需要注意的是, 在model中需要每次重新计算batch_size, 因为可能会出现一个batch,在最后的时候,不是自己设置的batch_size, 会比batch_size要小。
其他也没什么要注意的地方,自己敲一遍就明白了。
测试数据
首先我们定义一下device, 方便之后使用gpu进行计算。
- # --------------------
- # Device configuration
- # --------------------
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
在这里我们进行一遍前向传播,看一下model写得是否正确。
- # ------------------------------------
- # Test the model(输入一张图片查看输出)
- # ------------------------------------
- # 定义模型
- model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
- # 初始化模型的weight
- model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
- model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
- model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
- # 定义数据
- dataiter = iter(train_loader)
- images, labels = dataiter.next()
- model.hidden = model.init_hidden()
- logits = model(images.view(-1,28,28).to(device))
- print(logits[0:2])
- """
- tensor([[-0.2846, -0.1503, -0.1593, 0.5478, 0.6827, 0.3489, -0.2989, 0.4575,
- -0.2426, -0.0464],
- [-0.6708, -0.3025, -0.0205, 0.2242, 0.8470, 0.2654, -0.0381, 0.6646,
- -0.4479, 0.2523]], device='cuda:0', grad_fn=<SliceBackward>)
- """
训练模型
接下来就是模型得训练了,我们先定义loss函数和优化器。注意这里对系数进行了初始化,初始化为对角矩阵。
关于对角矩阵得使用,大致如下
- # 产生对角线是1的矩阵
- torch.eye(n=5, m=5, out=None)
- """
- tensor([[1., 0., 0., 0., 0.],
- [0., 1., 0., 0., 0.],
- [0., 0., 1., 0., 0.],
- [0., 0., 0., 1., 0.],
- [0., 0., 0., 0., 1.]])
- """
下面是训练前得一些准备工作。
- # --------
- # Training
- # --------
- model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.Adam(model.parameters(),lr=0.001)
- # 初始化模型的weight
- model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
- model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
- model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
- def get_accuracy(logit, target, batch_size):
- """最后用来计算模型的准确率
- """
- corrects = (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()
- accuracy = 100.0 * corrects/batch_size
- return accuracy.item()
接下来就可以开始训练了。
- # ---------
- # 开始训练
- # ---------
- for epoch in range(N_EPHOCS):
- train_running_loss = 0.0
- train_acc = 0.0
- model.train()
- # trainging round
- for i, data in enumerate(train_loader):
- optimizer.zero_grad()
- # reset hidden states
- model.hidden = model.init_hidden()
- # get inputs
- inputs, labels = data
- inputs = inputs.view(-1,28,28).to(device)
- labels = labels.to(device)
- # forward+backward+optimize
- outputs = model(inputs)
- loss = criterion(outputs, labels)
- loss.backward()
- optimizer.step()
- train_running_loss = train_running_loss + loss.detach().item()
- train_acc = train_acc + get_accuracy(outputs, labels, batch_size)
- model.eval()
- print('Epoch : {:0>2d} | Loss : {:<6.4f} | Train Accuracy : {:<6.2f}%'.format(epoch, train_running_loss/i, train_acc/i))
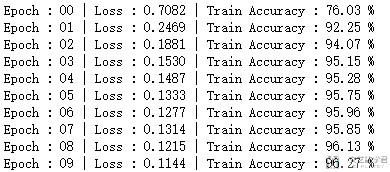
评价模型, 计算测试集准确率
最后拿上面得模型,在测试集上进行测试,准确率还是挺高得。
- # ----------------------------------------
- # Computer accuracy on the testing dataset
- # ----------------------------------------
- test_acc = 0.0
- for i,data in enumerate(test_loader,0):
- inputs, labels = data
- labels = labels.to(device)
- inputs = inputs.view(-1,28,28).to(device)
- outputs = model(inputs)
- thisBatchAcc = get_accuracy(outputs, labels, batch_size)
- print("Batch:{:0>2d}, Accuracy : {:<6.4f}%".format(i,thisBatchAcc))
- test_acc = test_acc + thisBatchAcc
- print('============平均准确率===========')
- print('Test Accuracy : {:<6.4f}%'.format(test_acc/i))
- """
- ============平均准确率===========
- Test Accuracy : 96.6026%
- """
定义hook, 查看中间过程
这里额外使用一下hook, 来看一下模型的中间的过程。有助于对RNN的理解吧。
- # 定义hook
- class SaveFeatures():
- """注册hook和移除hook
- """
- def __init__(self, module):
- self.hook = module.register_forward_hook(self.hook_fn)
- def hook_fn(self, module, input, output):
- self.features = output
- def close(self):
- self.hook.remove()
- # 绑定到model上
- activations = SaveFeatures(model.basic_rnn)
进行网络的传播。
- # 定义数据
- dataiter = iter(train_loader)
- images, labels = dataiter.next()
- # 前向传播
- model.hidden = model.init_hidden()
- logits = model(images.view(-1,28,28).to(device))
- activations.close() # 移除hook
查看一下中间输出数据的大小,可以理解一下为什么是28128150.
- # 这个是 28(step)*128(batch_size)*150(hidden_size)
- activations.features[0].shape
- # torch.Size([28, 128, 150])
- activations.features[0][-1].shape
- # torch.Size([128, 150])
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论