文章目录(Table of Contents)
前言
这一篇会介绍使用RNN,更详细一点是GRU来实现句子的情感分类。其实RNN的基本用法都是相同的,和RNN完成姓名分类,在做法上其实是很接近的。
不过在这一篇文章,我会把整个处理自然语言的流程过一篇,如前面的数据预处理,数据填充这一通用的部分。也是方便之后做相关内容的时候可以加快做的速度。(这一部分也是我自己的总结,可能会有写的不好的地方)
后面每一个大的章节我会讲一部分。
导入库
这个没什么好讲的,把需要使用的导入。
- import unicodedata
- import string
- import re
- import time
- import random
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- from sklearn.model_selection import train_test_split
- import pickle
- import torch
- import torch.nn as nn
- from torch import optim
- import torch.nn.functional as F
- import torch.utils.data as Data
- from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
导入数据
通常情况下,我们会将处理好的数据进行保存,来方便之后的使用.(不需要每次使用之前都进行预处理,所以先定义两个函数,用来导出和导入数据。)
- def convert_to_pickle(item, directory):
- """导出数据
- """
- pickle.dump(item, open(directory,"wb"))
- def load_from_pickle(directory):
- """导入数据
- """
- return pickle.load(open(directory,"rb"))
这次使用的数据是保存为csv的格式,我们将其读入:
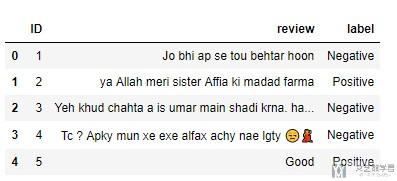
- data = pd.read_csv('./data/train.csv',lineterminator='\n',encoding='utf-8')
- data.head()
数据预处理
数据预处理是比较关键的一部分,也是可以通用的一部分。数据预处理大致分为下面几个部分.
- 将所有字母转为Ascii。
- 将大写都转换为小写; 同时, 只保留常用的标点符号
- 新建完成, word2idx, idx2word, word2count(每个单词出现的次数), n_word(总的单词个数)
- 去掉一些低频的词汇(有时也会去掉停用词);
- 将句子转换为Tensor, 每个word使用index来进行代替;
- 对句子进行填充, 使每句句子的长度相同, 这样可以使用batch进行训练(需要确定最终句子的长度)
- 将label转换为one-hot的格式, 方便最后的训练(Pytorch中只需要转换为标号即可)
下面我们逐个来讲一下是如何完成的。
转为Ascii&大小写转换与去掉标点&完成word2index等创建
这一部分主要是完成上面提到的数据预处理的前三个部分。函数如下所示。
- # 第一步数据预处理
- def unicodeToAscii(s):
- """转换为Ascii
- """
- return ''.join(
- c for c in unicodedata.normalize('NFD', s)
- if unicodedata.category(c) != 'Mn'
- )
- # 第二步数据预处理
- def normalizeString(s):
- """转换为小写, 同时去掉奇怪的符号
- """
- s = unicodeToAscii(s.lower().strip())
- s = re.sub(r"([.!?])", r" \1", s)
- s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
- return s
- # 第三步数据预处理
- class Lang():
- def __init__(self):
- self.word2index = {}
- self.word2count = {}
- # 初始的时候SOS表示句子开头(0还在padding的时候会进行填充), EOS表示句子结尾(或是表示没有加入index中的新的单词, 即不常用的单词)
- self.index2word = {0:"SOS",1:"EOS"}
- self.n_words = 2
- def addSentence(self, sentence):
- """把句子中的每个单词加入字典中
- """
- for word in sentence.split(' '):
- self.addWord(word)
- def addWord(self, word):
- if word not in self.word2index:
- self.word2index[word] = self.n_words # 新单词的标号
- self.word2count[word] = 1 # 新单词的个数
- self.index2word[self.n_words] = word
- self.n_words = self.n_words + 1
- else:
- self.word2count[word] = self.word2count[word] + 1
下面我们我们对上面导入的数据进行上面三步的预处理,最后可以得到一个类,包含word2index, index2word, word2count, n_word等属性。
- # 把数据集中的每句话中的单词进行转化
- lang = Lang()
- for sentence_data in data["review"].values.tolist():
- # 数据清洗
- sentence_data = normalizeString(sentence_data)
- # 增加word2index
- lang.addSentence(sentence_data)
- # 显示一些统计数据
- print("Count word:{}".format(lang.n_words))
- """
- Count word:17684
- """
去掉低频词汇
下面我们要去掉一些低频的词汇。那么是如何进行去除呢。我们首先要看一下他的统计上的特性。
我们首先看一下单词出现次数的中位数,平均数和最大值。(可以看到有很多单词只出现了一次)
- # 打印一下单词个数的分布
- data_count = np.array(list(lang.word2count.values()))
- # 有大量单词只出现了很少的次数
- np.median(data_count), np.mean(data_count), np.max(data_count)
- """
- (1.0, 5.799343965614749, 3033)
- """
接着我们查看一下出现次数<n的单词,占总的单词出现次数的比例:
- # 计算<n的单词, 出现次数占总的出现次数的比例
- less_count = 0
- total_count = 0
- for _,count in lang.word2count.items():
- if count < 2:
- less_count = less_count + count
- total_count = total_count + count
- print("小于N的单词出现次数 : ",less_count,
- "\n总的单词出现次数 : ",total_count,
- "\n小于N的单词占比 : ",less_count/total_count*100)
- """
- 小于N的单词出现次数 : 10547
- 总的单词出现次数 : 102544
- 小于N的单词占比 : 10.285340926821657
- """
有的时候,我们还会看一些<n的单词占总的单词的比例(注意这里和上面的区别,这里是不考虑单词出现的次数,只考虑单词的个数,即有多少个不同的单词)
- # 计算<n的单词, 出现个数占总的出现个数的比例
- less_count = 0
- total_count = 0
- for _,count in lang.word2count.items():
- if count < 2:
- less_count = less_count + 1
- total_count = total_count + 1
- print("小于N的单词出现个数 : ",less_count,
- "\n总的单词出现个数 : ",total_count,
- "\n小于N的单词占比 : ",less_count/total_count*100)
最后,我们去掉只出现了1次的单词。重新创建类(lang_process)
- # 我们设置单词至少出现2次
- lang_process = Lang()
- for word,count in lang.word2count.items():
- if count >= 2:
- lang_process.word2index[word] = lang_process.n_words # 新单词的标号
- lang_process.word2count[word] = count # 新单词的个数
- lang_process.index2word[lang_process.n_words] = word
- lang_process.n_words = lang_process.n_words + 1
- # 显示一些统计数据
- print("Count word:{}".format(lang_process.n_words))
- """
- Count word:7137
- """
我们简单查看一下每个单词出现的次数:
- # 简单查看一下lang_process留下的单词
- lang_process.word2count
- """
- {'jo': 319,
- 'bhi': 670,
- 'ap': 276,
- 'se': 1235,
- 'tou': 99,
- 'behtar': 43,
- """
到这里,比较建议把lang_process存储一下,之后就不用重新生成这个对应关系了。
- convert_to_pickle(lang_process, './data/lang_process.pkl')
将text转换为Tensor
需要注意的是,前面在生成word2index的时候, 都进行了单词的处理(大小写等)。所以现在将text转为tensor的时候,也需要注意这一点。(不然会有很多单词匹配不到对应的index, 可能是由于大小写等的原因)
于是下面将text转换为Tensor。
- # 把data中的句子按顺序转为tensor
- # 这里转换的时候,句子中的单词也是需要标准化的
- def convertWord2index(word):
- if lang_process.word2index.get(word)==None:
- # 一些出现次数很少的词汇使用1来表示
- return 1
- else:
- return lang_process.word2index.get(word)
- input_tensor = [[convertWord2index(s) for s in normalizeString(es).split(' ')] for es in data["review"].values.tolist()]
最后,我们简单看一下转换完之后,word和index是否是对应的。
- # 查看最后两句话的文字
- data["review"].values.tolist()[-2:]
- """
- ['Ma na suna ha lemon sa haddiyan kamzor hoti hn regular Lana sa?',
- 'Ball poar jadooi giraft se inhe rafter aur swing ko qaboo karne ka hairat angez fun aata hai']
- """
- # 查看最后两句话的index
- input_tensor[-2:]
- """
- [[192, 288, 1741, 239, 2065, 1552, 1, 4867, 169, 487, 5937, 181, 1552, 28],
- [5012,
- 1,
- 1,
- 3569,
- 5,
- 2386,
- 7113,
- 43,
- 1,
- 145,
- 1,
- 406,
- 49,
- 6395,
- 4930,
- 753,
- 1923,
- 84]]
- """
- # 这个index可以和word对应上(可以看到是忽略大小写的-这个很重要)
- lang_process.index2word[192]
- """
- 'ma'
- """
Word Padding
在这一步,我们将Tensor转换为定长的Tensor, 多余的去掉, 不足的补0。这一步是方便使用GPU计算。可以使用batch来进行加速计算。
那么首先,我们要确定一下最后统一之后句子的长度。我们首先看一下句子长度的统计信息。
- # 查看句子的平均长度, 长度的中位数, 最长的长度
- sentence_length = [len(t) for t in input_tensor]
- print(np.mean(sentence_length))
- print(np.median(sentence_length))
- print(np.max(sentence_length))
- """
- 16.20480404551201
- 12.0
- 313
- """
可以看到最长是313个字符,我们画一下柱状图,可以更加直观看到句子长度的分布。
- fig = plt.figure()
- ax = fig.add_subplot(1,1,1)
- bins = np.arange(0,300,10) # 产生区间刻度
- ax.hist(sentence_length,bins=bins)
- fig.show()
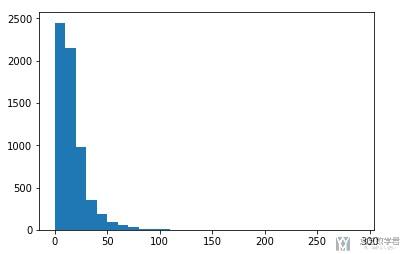
我们可以看到,主要集在在100以内。那么我们再细化一下,画一下细化后的分布图。
- fig = plt.figure()
- ax = fig.add_subplot(1,1,1)
- bins = np.arange(0,100,5) # 产生区间刻度
- ax.hist(sentence_length,bins=bins)
- fig.show()
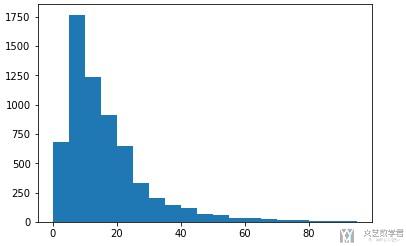
根据上面的图像, 我们可以知道, 句子长度取80是一个比较好的值。即超过80个单词的句子去掉后面的部分, 少于80个单词的句子后面补充0。
- def pad_sequences(x, max_len):
- """定义自动填充的函数
- """
- padded = np.zeros((max_len), dtype=np.int64)
- if len(x) > max_len:
- padded[:] = x[:max_len]
- else:
- padded[:len(x)] = x
- return padded
接下来进行padding,并简单查看一下padding之后的结果。
- input_tensor = [pad_sequences(x, 80) for x in input_tensor]
- # 查看一下完成填充之后的数据
- input_tensor[-2:]
- """
- [array([ 192, 288, 1741, 239, 2065, 1552, 1, 4867, 169, 487, 5937,
- 181, 1552, 28, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0], dtype=int64),
- array([5012, 1, 1, 3569, 5, 2386, 7113, 43, 1, 145, 1,
- 406, 49, 6395, 4930, 753, 1923, 84, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
- 0, 0, 0], dtype=int64)]
- """
将Label转为index(one-hot的格式)
接下来就是数据预处理的最后一部分,我们需要处理一下label的数据。在PyTorch中,只需要转换为标号即可。
我们首先查看一下有多少个分类。
- # 查看一下所有的分类
- data['label'].unique()
- """
- array(['Negative', 'Positive'], dtype=object)
- """
接着我们对label进行转换
- index2emotion = {0: 'Negative', 1: 'Positive'}
- emotion2index = {'Negative' : 0, 'Positive' : 1}
- target_tensor = [emotion2index.get(s) for s in data['label'].values.tolist()]
- # 简单查看一下样本
- target_tensor[:10]
- """
- [0, 1, 0, 0, 1, 0, 0, 1, 1, 0]
- """
到这里我们就基本完成了数据的预处理的部分。到这里我自己通常会将target_tensor和input_tensor保存一下,之后就不用在进行重复的数据预处理了。
数据的保存
- convert_to_pickle(input_tensor, './data/input_tensor.pkl')
- convert_to_pickle(target_tensor, './data/target_tensor.pkl')
到这里,数据集的预处理就已经全部处理好了,下面就是创建Data Loader, 最后可以用来放入整个模型中去。
Data Loader
这一部分主要有下面的两个步骤来完成。
- 数据集的划分, 训练集和测试集
- 数据集的加载, 使用DataLoader来加载数据集
数据集的划分
首先,我们完成数据集的划分,我们划出10%作为测试来使用。
- # 数据集的划分(这里全部是训练集)
- END = int(len(input_tensor)*0.9)
- # 将数据转为tensor的数据格式
- input_tensor_train = torch.from_numpy(np.array(input_tensor[:END]))
- target_tensor_train = torch.from_numpy(np.array(target_tensor[:END])).long()
- input_tensor_test = torch.from_numpy(np.array(input_tensor[END:]))
- target_tensor_test = torch.from_numpy(np.array(target_tensor[END:])).long()
- # Show length
- len(input_tensor_train), len(target_tensor_train), len(input_tensor_test), len(target_tensor_test)
- """
- (5695, 5695, 633, 633)
- """
创建DataLoader
接下来,我们创建dataloader,方便之后Pytorch进行训练。
- # 加载dataloader
- train_dataset = Data.TensorDataset(input_tensor_train, target_tensor_train) # 训练样本
- test_dataset = Data.TensorDataset(input_tensor_test, target_tensor_test) # 测试样本
- MINIBATCH_SIZE = 64
- train_loader = Data.DataLoader(
- dataset=train_dataset,
- batch_size=MINIBATCH_SIZE,
- shuffle=True,
- num_workers=2 # set multi-work num read data
- )
- test_loader = Data.DataLoader(
- dataset=test_dataset,
- batch_size=MINIBATCH_SIZE,
- shuffle=True,
- num_workers=2 # set multi-work num read data
- )
到这里,就创建好了dataload, 后面就可以开始构建网络,可以开始训练了。
创建Model
后面的内容就是和之前这篇RNN完成姓名分类是一样的了。
模型的建立
- # GRU的model
- class EmotionGRU(nn.Module):
- def __init__(self, vocab_size, embedding_dim, hidden_units, batch_sz, output_size, layers=2):
- super(EmotionGRU, self).__init__()
- self.vocab_size = vocab_size # 总的单词的个数
- self.embedding_dim = embedding_dim
- self.hidden_units = hidden_units
- self.batch_sz = batch_sz
- self.output_size = output_size
- self.num_layers = layers
- # layers
- self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim) # 可以将标号转为向量
- self.dropout = nn.Dropout(0.5)
- self.gru = nn.GRU(self.embedding_dim, self.hidden_units, num_layers=self.num_layers, batch_first = True, bidirectional=True, dropout=0.5)
- self.fc = nn.Linear(self.hidden_units*2, self.output_size)
- def init_hidden(self):
- # 使用了双向RNN, 所以num_layer*2
- return torch.zeros((self.num_layers*2, self.batch_sz, self.hidden_units)).to(device)
- def forward(self,x):
- self.batch_sz = x.size(0)
- # print(x.shape)
- x = self.embedding(x)
- # print(x.shape)
- self.hidden = self.init_hidden()
- output, self.hidden = self.gru(x, self.hidden)
- # print(output.shape)
- # 因为是 batch*seq*output, 所以要取最后一个seq
- output = output[:,-1,:]
- output = self.dropout(output)
- output = self.fc(output)
- # print(output.shape)
- return output
模型的测试
在正式开始训练之前,我们首先测试一下模型是否正常运行,最后输出的结果的size是否是和我们预期是一样的。
- # 测试模型
- vocab_inp_size = len(lang_process.word2index)
- embedding_dim = 256
- hidden_units = 512
- target_size = 2 # 一共有2种emotion
- layers = 3
- # 测试模型
- model = EmotionGRU(vocab_inp_size, embedding_dim, hidden_units, MINIBATCH_SIZE, target_size, layers).to(device)
- # 测试数据
- it = iter(train_loader)
- x, y = next(it)
- output = model(x.to(device))
- # 64*2, 表示一共有64个样本, 每个样本是2个emotion的概率
- output.size()
- """
- torch.Size([64, 2])
- """
训练模型
- 定义辅助函数(这里是计算准确率的函数)
- 定义损失函数和优化器
- 开始训练
定义辅助函数
- def accuracy(target, logit):
- ''' Obtain accuracy for training round '''
- target = torch.max(target, 1)[1] # convert from one-hot encoding to class indices
- corrects = (logit == target).sum()
- accuracy = 100.0 * corrects / len(logit)
- return accuracy
定义损失函数, 优化器和开始优化
- # 模型超参数
- vocab_inp_size = len(lang_process.word2index)
- embedding_dim = 256
- hidden_units = 512
- target_size = 2 # 一共有6种emotion
- num_layers = [1,2,3]
- for layers in num_layers:
- # 测试模型
- modelGRU = EmotionGRU(vocab_inp_size, embedding_dim, hidden_units, MINIBATCH_SIZE, target_size, layers).to(device)
- modelLSTM = EmotionLSTM(vocab_inp_size, embedding_dim, hidden_units, MINIBATCH_SIZE, target_size, layers).to(device)
- models = {'GRU':modelGRU, 'LSTM',modelLSTM}
- for key, model in models.items():
- # 定义损失函数和优化器
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.Adam(model.parameters(),lr=0.001)
- # 开始训练
- num_epochs = 25
- for epoch in range(num_epochs):
- start = time.time()
- train_total_loss = 0 # 记录一整个epoch中的平均loss
- train_total_accuracy = 0 # 记录一整个epoch中的平均accuracy
- ### Training
- for batch, (inp, targ) in enumerate(train_loader):
- predictions = model(inp.to(device))
- # 计算误差
- loss = criterion(predictions, targ.to(device))
- # 反向传播, 修改weight
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- # 记录Loss下降和准确率的提升
- batch_loss = (loss / int(targ.size(0))) # 记录一个bacth的loss
- batch_accuracy = accuracy(predictions, targ.to(device))
- train_total_loss = train_total_loss + batch_loss
- train_total_accuracy = train_total_accuracy + batch_accuracy
- if batch % 25 == 0:
- record_train_accuracy = train_total_accuracy.cpu().detach().numpy()/(batch+1)
- print('Epoch {} Batch {} Accuracy {:.4f}. Loss {:.4f}'.format(epoch + 1,
- batch,
- train_total_accuracy.cpu().detach().numpy()/(batch+1),
- train_total_loss.cpu().detach().numpy()/(batch+1)))
- # 每一个epoch来计算在test上的准确率
- print('------------')
- model.eval()
- test_total_accuracy = 0
- for batch, (input_data, target_data) in enumerate(test_loader):
- predictions = model(input_data.to(device))
- batch_accuracy = accuracy(predictions, target_data.to(device))
- test_total_accuracy = test_total_accuracy + batch_accuracy
- print('Test : Lay {}, Model {}, Epoch {} Accuracy {:.4f}'.format(layers, key, epoch + 1, test_total_accuracy.cpu().detach().numpy()/(batch+1)))
- record_test_accuracy = test_total_accuracy.cpu().detach().numpy()/(batch+1)
- if epoch == num_epochs - 1:
- # 把最后一轮的结果写入文件
- with open('byr.txt','a') as file:
- file.write('{},{},{:.4f},{:.4f}'.format(key,layers,record_train_accuracy,record_test_accuracy))
- print('============')
到这里就开始训练,并每个epoch会打印在测试集上的效果。
模型的保存
最后一步,我们将上面的模型进行保存即可。
- # 保存模型
- torch.save(model, 'EmotionRNN.pkl')
结语
到这里,就完成了整个RNN用于感情分类的步骤。这里最主要的步骤,还是 记录一下整个处理自然语言时的步骤。只是我自己的一个整理,可能并不是很完整。
完整的代码见下面的链接 : Emotion RNN(RNN用于语句情感分类)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论