文章目录(Table of Contents)
简介
这一篇文章主要会介绍一下WGAN-GP的训练方式. 也是使用这一个例子, 来说明一下在训练GAN的时候的一些常用的步骤, 包括定义网络, 网络的测试(设置测试集), 训练分类器和生成器的步骤, 模型的保存和使用, 结果的展示.
下面会就每一个部分分别进行解释. 同时原始的notebook也是已经上传了github, 链接地址如下所示.
代码仓库链接: GAN的代码仓库
实践步骤
准备工作
在这里我们导入我们需要使用的库, 同时我们需要定义device, 也就是训练的时候使用cpu还是gpu.
- import numpy as np
- import pandas as pd
- import os
- import matplotlib.pyplot as plt
- from datetime import date,datetime
- import logging
- import torch
- from torch import nn
- from torchvision import datasets, transforms
- from torch import optim
- from torch.autograd import Variable
- from torchvision.utils import make_grid
- from torchvision.utils import save_image
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- device
定义网络
接着我们来定义网络, 我们首先定义分类器(discriminator), 这里我们是用来做动漫头像的分类.
- class Discriminator(nn.Module):
- def __init__(self):
- super(Discriminator, self).__init__()
- self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False)
- self.batchN1 = nn.BatchNorm2d(64)
- self.LeakyReLU1 = nn.LeakyReLU(0.2, inplace=True)
- self.conv2 = nn.Conv2d(in_channels=64, out_channels=64*2, kernel_size=4, stride=2, padding=1, bias=False)
- self.batchN2 = nn.BatchNorm2d(64*2)
- self.LeakyReLU2 = nn.LeakyReLU(0.2, inplace=True)
- self.conv3 = nn.Conv2d(in_channels=64*2, out_channels=64*4, kernel_size=4, stride=2, padding=1, bias=False)
- self.batchN3 = nn.BatchNorm2d(64*4)
- self.LeakyReLU3 = nn.LeakyReLU(0.2, inplace=True)
- self.conv4 = nn.Conv2d(in_channels=64*4, out_channels=64*8, kernel_size=4, stride=2, padding=1, bias=False)
- self.batchN4 = nn.BatchNorm2d(64*8)
- self.LeakyReLU4 = nn.LeakyReLU(0.2, inplace=True)
- self.conv5 = nn.Conv2d(in_channels=64*8, out_channels=1, kernel_size=4, bias=False)
- self.sigmoid = nn.Sigmoid()
- def forward(self, x):
- x = self.LeakyReLU1(self.batchN1(self.conv1(x)))
- x = self.LeakyReLU2(self.batchN2(self.conv2(x)))
- x = self.LeakyReLU3(self.batchN3(self.conv3(x)))
- x = self.LeakyReLU4(self.batchN4(self.conv4(x)))
- x = self.conv5(x)
- return x
我们有的时候会测试一下我们的D是否是正确的, 于是我们可以从训练样本中抽取出一些来进行测试.
- # 真实的图片
- images = torch.stack(([dataset[i][0] for i in range(batch_size)]))
- # 测试D是否与想象的是一样的
- outputs = D(images)
接着我们定义生成器(generator), 生成器是输入随机数, 生成我们要模仿的动漫头像(Anime-Face)
- class Generator(nn.Module):
- def __init__(self):
- super(Generator, self).__init__()
- self.ConvT1 = nn.ConvTranspose2d(in_channels=100, out_channels=64*8, kernel_size=4, bias=False) # 这里的in_channels是和初始的随机数有关
- self.batchN1 = nn.BatchNorm2d(64*8)
- self.relu1 = nn.ReLU()
- self.ConvT2 = nn.ConvTranspose2d(in_channels=64*8, out_channels=64*4, kernel_size=4, stride=2, padding=1, bias=False) # 这里的in_channels是和初始的随机数有关
- self.batchN2 = nn.BatchNorm2d(64*4)
- self.relu2 = nn.ReLU()
- self.ConvT3= nn.ConvTranspose2d(in_channels=64*4, out_channels=64*2, kernel_size=4, stride=2, padding=1, bias=False) # 这里的in_channels是和初始的随机数有关
- self.batchN3 = nn.BatchNorm2d(64*2)
- self.relu3 = nn.ReLU()
- self.ConvT4 = nn.ConvTranspose2d(in_channels=64*2, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False) # 这里的in_channels是和初始的随机数有关
- self.batchN4 = nn.BatchNorm2d(64)
- self.relu4 = nn.ReLU()
- self.ConvT5 = nn.ConvTranspose2d(in_channels=64, out_channels=3, kernel_size=4, stride=2, padding=1, bias=False)
- self.tanh = nn.Tanh() # 激活函数
- def forward(self, x):
- x = self.relu1(self.batchN1(self.ConvT1(x)))
- x = self.relu2(self.batchN2(self.ConvT2(x)))
- x = self.relu3(self.batchN3(self.ConvT3(x)))
- x = self.relu4(self.batchN4(self.ConvT4(x)))
- x = self.ConvT5(x)
- x = self.tanh(x)
- return x
同样的, 我们可以测试一下G是否是和我们想象中是一样进行工作的. 我们使用下面的方式进行测试.
- noise = Variable(torch.randn(batch_size, 100, 1, 1)).to(device) # 随机噪声,生成器输入
- # 测试G
- fake_images = G(noise)
加载数据集&定义辅助函数
在这一部分我们进行数据集的加载. 因为我数据集已经提前下载好了, 直接使用pytorch中的dataset即可. 这一部分的使用可以参考这个链接: Pytorch图像处理,显示与保存
我们在图像导入的时候, 首先将其变为64*64的大小, 同时进行归一化, 使其像素值的范围变为(-1,1). 这样于generator最后的tanh也是可以对应起来.
- trans = transforms.Compose([
- transforms.Resize(64),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- dataset = datasets.ImageFolder('./data', transform=trans) # 数据路径
- dataloader = torch.utils.data.DataLoader(dataset,
- batch_size=128, # 批量大小
- shuffle=True, # 乱序
- num_workers=2 # 多进程
- )
因为我们进行了归一化, 所以在图像最后进行保存的时候, 我们需要进行还原, 所以我们定义一个辅助函数来帮助进行还原.
- # 图像像素还原
- def denorm(x):
- out = (x + 1) / 2
- return out.clamp(0, 1)
开始训练
接下来就可以开始进行训练了. 这里训练主要分为三个步骤, 首先是初始化网络, 定义损失函数和优化器. 接着我们就是分别训练分类器和优化器.
初始化网络和优化器
这里一部分没有什么特别要说明的, 就是和其他的网络训练是一样的.
- # ----------
- # 初始化网络
- # ----------
- D = Discriminator().to(device) # 定义分类器
- G = Generator().to(device) # 定义生成器
- # -----------------------
- # 定义损失函数和优化器
- # -----------------------
- learning_rate = 0.0002
- d_optimizer = torch.optim.Adam(D.parameters(), lr=learning_rate)
- g_optimizer = torch.optim.Adam(G.parameters(), lr=learning_rate)
训练Discriminator
接着我们训练分类器(discriminator), 在训练WGAN-GP的discriminator的时候, 他是由三个部分的loss来组成的. 下面我们来每一步进行分解了进行查看.
首先我们定义好要使用的real_label=1和fake_label=0, 和G需要使用的noise.
- # 测试时的batch大小
- batch_size = 36
- # 创造real label和fake label
- real_labels = torch.ones(batch_size, 1).to(device) # real的pic的label都是1
- fake_labels = torch.zeros(batch_size, 1).to(device) # fake的pic的label都是0
- noise = Variable(torch.randn(batch_size, 100, 1, 1)).to(device) # 随机噪声,生成器输入
- # 真实的图片
- images = torch.stack(([dataset[i][0] for i in range(batch_size)]))
接着我们计算loss的第一个组成部分(这里参考WGAN-GP的loss的计算公式).
- # 首先计算真实的图片的loss, d_loss_real
- outputs = D(images)
- d_loss_real = -torch.mean(outputs)
接着我们计算loss的第二个组成部分.
- # 接着计算假的图片的loss, d_loss_fake
- fake_images = G(noise)
- outputs = D(fake_images)
- d_loss_fake = torch.mean(outputs)
接着我们计算penalty region的loss, 也就是我们希望在penalty region中的梯度是越接近1越好.
我们首先生成penalty region, 这一部分是在P_G和P_data之间的, 如下图所示.
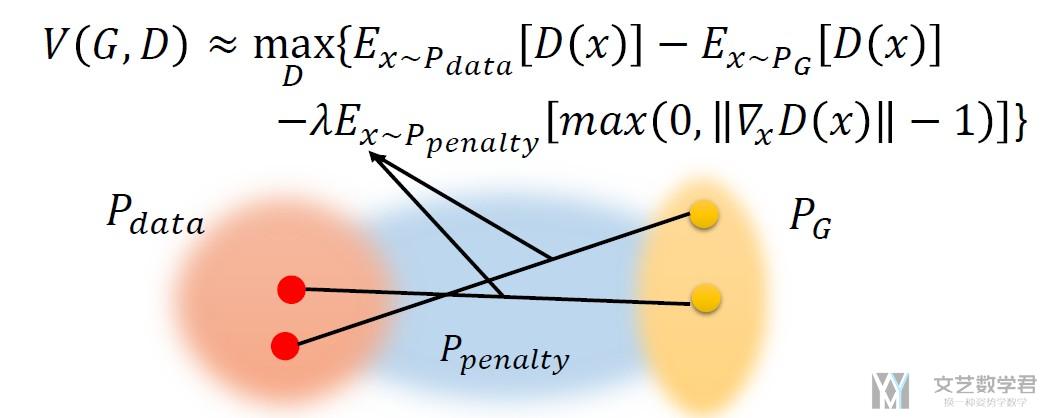
- # 接着计算penalty region 的loss, d_loss_penalty
- # 生成penalty region
- alpha = torch.rand((batch_size, 1, 1, 1)).to(device)
- x_hat = alpha * images.data + (1 - alpha) * fake_images.data
- x_hat.requires_grad = True
接着我们来计算他们的梯度, 我们希望梯度是越接近1越好.
- # 将中间的值进行分类
- pred_hat = D(x_hat)
- # 计算梯度
- gradient = torch.autograd.grad(outputs=pred_hat, inputs=x_hat, grad_outputs=torch.ones(pred_hat.size()).to(device),
- create_graph=False, retain_graph=False)
这里的梯度计算完毕之后是在每一个像素点处都是有梯度的值的.
- # 计算出每一张图, 每一个像素点处的梯度
- gradient[0].shape
- """
- torch.Size([36, 3, 64, 64])
- """
接着我们计算L2范数.
- penalty_lambda = 10 # 梯度惩罚系数
- gradient_penalty = penalty_lambda * ((gradient[0].view(gradient[0].size()[0], -1).norm(p=2,dim=1)-1)**2).mean()
- gradient_penalty
最后只需要把上面的三个部分相加, 进行反向传播来进行优化即可.
- # 三个loss相加, 反向传播进行优化
- d_loss = d_loss_real + d_loss_fake + gradient_penalty
- g_optimizer.zero_grad() # 两个优化器梯度都要清0
- d_optimizer.zero_grad()
- d_loss.backward()
- d_optimizer.step()
训练Generator
WGAN-GP优化器部分的训练和其他的没有什么太大的不同, 我们这里就简单说明一下即可.
- normal_noise = Variable(torch.randn(batch_size, 100, 1, 1)).normal_(0, 1).to(device)
- fake_images = G(normal_noise) # 生成假的图片
- outputs = D(fake_images) # 放入辨别器
- g_loss = -torch.mean(outputs) # 希望生成器生成的图片判别器可以判别为真
- d_optimizer.zero_grad()
- g_optimizer.zero_grad()
- g_loss.backward()
- g_optimizer.step()
到这里基本所有的步骤就完毕了, 后面就是开始训练就可以了. 我们后面直接看一下训练完毕之后的结果.
结果展示
我们将上面的步骤重复N次, 反复训练D和G, 并将结果进行保存. 下面我们来看一下最后生成器生成的效果.
首先我们导入已经训练好的模型.
- G = Generator().to(device) # 定义生成器
- # 读入生成器的模型
- G.load_state_dict(torch.load('./models/G.ckpt', map_location='cpu'))
接着我们使用G来进行图像的生成, 并显示出来. 在这之前, 我们首先定义一个函数来帮助我们进行显示.
- def show(img):
- """
- 用来显示图片的
- """
- plt.figure(figsize=(24, 16))
- npimg = img.detach().numpy()
- plt.imshow(np.transpose(npimg, (1,2,0)), interpolation='nearest')
最后就是查看显示的结果了.
- # 使用生成器来进行生成
- test_noise = Variable(torch.FloatTensor(40, 100, 1, 1).normal_(0, 1)).to(device)
- fake_image = G(test_noise)
- show(make_grid(fake_image, nrow=8, padding=1, normalize=True, range=(-1, 1), scale_each=False, pad_value=0.5))
最终显示的结果如下所示, 可以看到不仔细看还是可以的:

训练结果的渐变
这里我们随机选择两张图片A, B; 作为对角线两端的图片. 接着我们将A的前50个变量在x轴缓慢变为B的前50个变量; 将A的后50个变量在y轴缓慢变为B的后50个变量, 于是就可以得到一个从A到B变换过程的图片.
我们首先随机取出两个图片.
- test_noise = Variable(torch.FloatTensor(2, 100, 1, 1).normal_(0, 1)).to(device)
- fake_image = G(test_noise)
- show(make_grid(fake_image, nrow=2, padding=1, normalize=True, range=(-1, 1), scale_each=False, pad_value=0.5))

接着定义左上角和右下角的图片.
- leftTop = test_noise[0] # 左上角图片
- rightBottom = test_noise[1] # 右下角图片
最后我们进行生成他们的中间值,
- # 生成10*10的noise, 用来作为输入进行生成
- interval = 10 # 图片的大小
- rowAdd = [(leftTop[i]-rightBottom[i])/interval for i in range(0,50)] # 每一行每一格变化的长度
- rowAddNums = [[leftTop[i] - rowAdd[i]*k for k in range(interval+1) ] for i in range(0,50)] # 变换后每一格的值
- rowAddNums = np.transpose(np.array(rowAddNums))
- columnAdd = [(leftTop[j]-rightBottom[j])/interval for j in range(50,100)] # 每一列每一格变化的长度
- columnAddNums = [[leftTop[j] - columnAdd[j-50]*k for k in range(interval+1)] for j in range(50,100)] # 变换后每一格的值
- columnAddNums = np.transpose(np.array(columnAddNums))
- InterpolationNoise = leftTop.unsqueeze(0)
- for columnAddNum in columnAddNums:
- for rowAddNum in rowAddNums:
- for i in range(0, 50):
- leftTop[i] = torch.tensor(rowAddNum[i])
- for j in range(50, 100):
- leftTop[j] = torch.tensor(columnAddNum[j-50])
- InterpolationNoise = torch.cat((InterpolationNoise, leftTop.unsqueeze(0)), dim=0)
最后进行可视化即可.
- fake_image = G(InterpolationNoise[1:])
- show(make_grid(fake_image, nrow=11, padding=1, normalize=True, range=(-1, 1), scale_each=False, pad_value=0.5))
下面我们来放一些最终比较好的结果. 简单放三张结果图.



训练不同轮数的结果展示
下面我们看一下训练不同epoch后的结果, 看一下逐渐变化的过程.
第一轮

第十轮

第五十轮

第一百轮
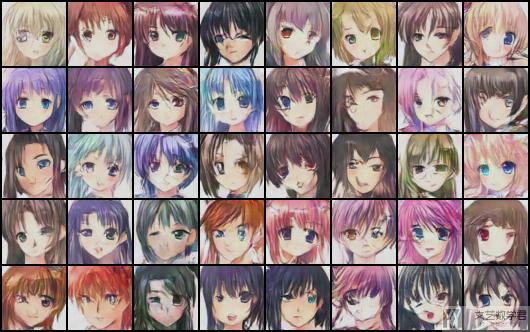
第两百轮

第五百轮

第一千轮

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












2020年10月30日 下午5:35 1F
你好,我调试了一下代码,我这里生成的图像全是噪声图?
2020年10月31日 下午2:22 B1
@ cy 你大概训练了多少轮, 超参数的设置是否一样. Github 上有完整的实验代码,你可以直接运行一下。
2020年11月2日 下午8:35 B2
@ 王 茂南 谢谢,楼主,我这面的结果已调好了,但是存在几个疑问
1.gp中loss为什么很大?而wgan中loss趋近与0.5与-0.5
2.在gp论文中指出在判别器不使用batchnorm或则是用layernorm
2020年11月2日 下午8:48 B2
@ 王 茂南 楼主,我这面已经调试出结果了,但是有个疑问,
(1)gp的loss为什么出现这么大的值,而wgan的loss稳定在0.5左右