文章目录(Table of Contents)
简介
这一篇文章我们主要会介绍在使用Pytorch的时候, 我们的数据集是图像的时候的一些操作. 之前也是零散的写过一些pytorch中图像的处理, 如Pytorch中图片数据集处理方式,我们在这里集中的描述一下.
这里主要会介绍以下的内容:
- 图像的标准化, 为什么要使用0.5来作为标准化的值.
- 使用ImageFolder来完成图片数据集的导入.
- 使用make_grid来完成图像的显示.
- 使用save_image来完成图像的保存.
同时, 会增加一部分, 直接使用cv2来对整个文件夹内的图片进行处理, 并生成新的图片. 关于opencv的更多内容, 可以查看文章图像处理-matplotlib显示opencv图像
使用cv2处理图像
有的时候, 我们希望直接对原始的图像进行处理, 并将处理好的图像保存下来, 这个时候就可以直接使用cv2进行处理. 下面看一个例子, 实现关于:
- 调整原始图片的大小
- 将原始图片转换为灰度图
- # 将图片重新存储
- # - 调整大小
- # - 调整为灰色
- def image_preprocess(dir_path='./dogs_cats_gray/cat/'):
- """图片预处理
- """
- i = 0
- for img in tqdm(os.listdir(dir_path)): # 调用 tqdm 可视化循环处理过程
- img_path = os.path.join(dir_path, img) # 图像的完整路径
- img_data = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) # 使用 opencv读取图像
- img_data = cv2.resize(img_data, (64, 64)) # 图片处理成统一大小
- os.remove(img_path) # 删除原始图像
- cv2.imwrite(img_path, img_data)# 保存新的图像
- i = i + 1
- if i%5000 == 0:
- print('i:',i,'img_name:',img,image_label(img))
关于使用cv2来进行图像的显示, 可以使用imshow来进行显示.
- import cv2
- # 查看两张图片
- img_path1 = "./dogs_cats/cat/cat.7.jpg"
- img_check1 = cv2.imread(img_path1, cv2.IMREAD_GRAYSCALE)
- img_path2 = "./dogs_cats/dog/dog.8.jpg"
- img_check2 = cv2.imread(img_path2, cv2.IMREAD_GRAYSCALE)
- # 显示图片
- fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(13,7))
- axes[0].imshow(img_check1,'gray')
- axes[1].imshow(img_check2,'gray')
Pytorch图像处理
图像的标准化
我们通常会使用如下的方式对图像进行处理, 我们会控制图像的大小, 转换为tensor, 同时进行标准化.
- trans = transforms.Compose([
- transforms.Resize(64),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
下面简单说明以下为什么标准化里的参数都是0.5, 这可以保证标准化之后的图像的像素值在-1到1之间. 这是因为: For example, the minimum value 0 will be converted to (0-0.5)/0.5=-1, the maximum value of 1 will be converted to (1-0.5)/0.5=1.
我们可以使用下面的方式将像素值进行还原: image = ((image * std) + mean)
参考资料: Understanding transform.Normalize( )
图像的导入
接着就是图像进行导入, 在pytorch中图像的导入也是十分方便的, 我们可以使用如下的方式进行图像的导入.
- # 注意这里文件夹的路径
- dataset = datasets.ImageFolder('./data', transform=trans) # 数据路径
- dataloader = torch.utils.data.DataLoader(dataset,
- batch_size=16, # 批量大小
- shuffle=True, # 乱序
- num_workers=2 # 多进程
- )
我们需要注意文件夹的路径的设置.
- root/dog/xxx.png
- root/dog/xxy.png
- root/dog/xxz.png
- root/cat/123.png
- root/cat/nsdf3.png
- root/cat/asd932_.png
就是他只需要写到root目录, 然后把每一类图片分别放在对应的文件夹内. 我们不能直接将图片放在root目录下, 不然就会出现如下的报错: RuntimeError: Found 0 images in subfolders of: ./data
上面报错解决链接: RuntimeError: Found 0 images in subfolders of: ./data
使用make_grid显示图像
接着我们说明以下make_grid的使用方式, 他可以方便的进行图片的显示, 下面简单说一下使用的方式, 具体的使用方式可以参考官方的文档: TORCHVISION.UTILS
make_grid可以使得图像按照网格进行排列, 我们下面来看一个例子. 也讲一下其中的参数的作用.
- from torchvision.utils import make_grid
- from torchvision.utils import save_image
定义show函数, 用来显示图片. 图像的大小可以在这里进行修改(figsize).
- def show(img):
- """
- 用来显示图片的
- """
- plt.figure(figsize=(12, 8))
- npimg = img.numpy()
- plt.imshow(np.transpose(npimg, (1,2,0)), interpolation='nearest')
接着我们先随便看一个例子
- show(make_grid(test_pic, nrow=6, padding=2, normalize=True, range=None, scale_each=False, pad_value=0))
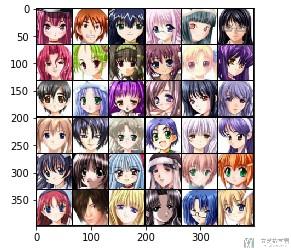
我们可以通过修改nrow来修改每一行的图片的数量, 同时padding表示图片之间的间距, pad_value表示图片之间填充的颜色. 我们可以分别来看下面的两个例子.
- show(make_grid(test_pic, nrow=8, padding=1, normalize=True, range=(-1, 1), scale_each=False, pad_value=0.5))
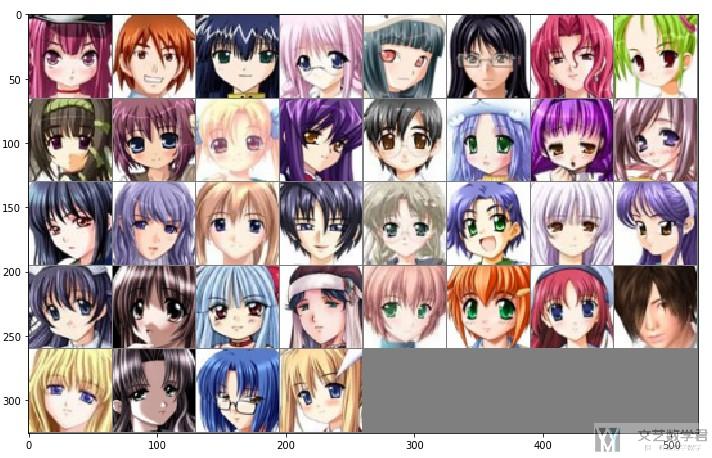
下面的padding就比较大, 可以很明显的看出区别来.
- # padding: 图片与图片之间的空隙
- # pad_value: 填充的颜色
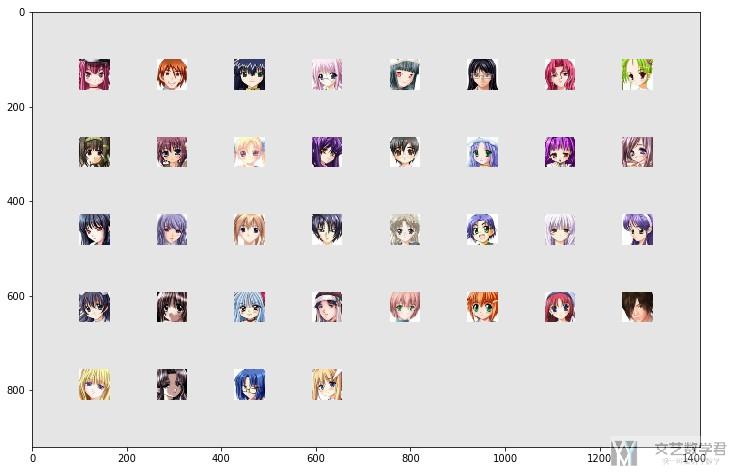
- show(make_grid(test_pic, nrow=8, padding=100, normalize=True, range=(-1, 1), scale_each=False, pad_value=0.9))
使用save_image保存图像
关于save_image的主要参数和上面的make_grid是一样的, 这里就不多做介绍, 就直接看一下例子.
- save_image(test_pic, 'test.png', nrow=6, padding=2, normalize=True, range=(-1,1), scale_each=False, pad_value=0)
最终保存的图片如下所示.

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论