文章目录(Table of Contents)
简介
我们会使用这个例子来给出一个Pytorch完整的训练模型的例子, 从数据处理到模型的构建和模型的训练. 之前我也是写过这个, PyTorch快速使用介绍–实现分类, 但这一篇文章已经是很久之前写的了, 所以这次更新一下, 结合一些我新知道的知识.
同时, 这一篇也会包含关于LIME与pytorch结合的例子. LIME我们在模型解释-LIME的原理和实现里讲过了, 但是那里最后给的例子不是很完善, 这里就正好给出一个完整的例子.
关于项目的完整代码, 参考Github网址: LIME与Pytorch结合使用
下面会分为两个部分来讲:
- 首先是描述Pytorch的完整训练的过程.
- 接着对训练好的模型, 使用LIME来进行解释.
Pytorch完整实例
这里我们使用Iris dataset作为数据集来搭建一个多分类的网络.
准备工作
我们首先导入我们需要使用的库, 首先是处理数据需要使用的.
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.preprocessing import StandardScaler
- %matplotlib inline
接着是Pytorch相关的库.
- import torch
- import torch.nn as nn
- import torch.utils.data as Data
数据处理
这里的主要工作包括:
- 数据导入+数据乱序
- 将label转换为id
- 数据标准化
- 划分训练集和测试集
- 将数据转换为tensor
- 构建dataset和dataloader
数据导入与数据乱序
首先我们导入数据, 需要注意的时候, 我们导入数据的时候可以对数据进行乱序.
- df = pd.read_csv('./iris.csv', names=['sepal length','sepal width','petal length','petal width','target'])
- df = df.sample(frac=1) # 乱序
- df.head()
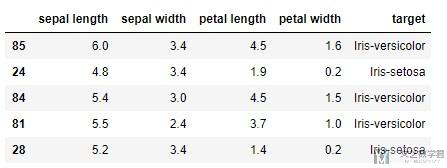
数据处理, label转id与标准化
我们可以看到上面target部分是文字显示的, 我们需要将其转换为对应的id. 同时我们需要对特征数据进行标准化.
我们定义一个字典类型用来将label转换为id.
- label_to_idx = {
- 'Iris-versicolor':0,
- 'Iris-virginica':1,
- 'Iris-setosa':2
- }
下面我们把数据分为x和y, 同时对数据进行标准化.
- # 数据标准化
- features = ['sepal length', 'sepal width', 'petal length', 'petal width']
- # Separating out the features
- x = df.loc[:, features].values
- # Separating out the target
- y = df.loc[:,['target']].values
- # 将label转换为id
- y_label = [label_to_idx[yy[0]] for yy in y]
- # Standardizing the features
- x = StandardScaler().fit_transform(x)
我们查看一下标准化后的数据.
- # 查看标准化之后的数据
- pd.DataFrame(data = x, columns = features).head()
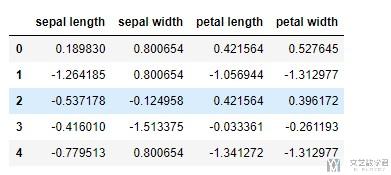
上面的数据:
- y是原始的label
- y_label是对应的id,
我们之后就使用y_label.
训练集测试集划分
接下来我们划分训练集和测试集.
- # 构建数据集(20%作为测试集合)
- X_train,Y_train,X_test,Y_test = x[:-30],y_label[:-30],x[-30:],y_label[-30:]
numpy转换为tensor
接着我们要将上面的numpy的数据转换为tensor, 方便之后训练网络的时候使用.
- X_train = torch.from_numpy(X_train).float() # 输入 x 张量
- X_test = torch.from_numpy(X_test).float()
- Y_train = torch.from_numpy(np.array(Y_train)).long() # 输入 y 张量
- Y_test = torch.from_numpy(np.array(Y_test)).long()
构建dataset与dataloader
最后, 我们构建dataset和dataloader即可.
- batch_size=10
- # Dataset
- train_dataset = Data.TensorDataset(X_train, Y_train)
- test_dataset = Data.TensorDataset(X_test, Y_test)
- # Data loader
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=batch_size,
- shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=False)
网络的构建
接下来就是网络的构建, 这一部分大致可以分为两个部分:
- 网络的定义
- 网络的训练
网络的定义
我们对于上面的多分类的问题, 使用全连接网络即可.
- # 网络的构建
- class NeuralNet(nn.Module):
- def __init__(self, input_size, hidden_size, num_classes, n_layers):
- super(NeuralNet, self).__init__()
- layers = []
- for i in range(n_layers):
- layers.append(nn.Linear(hidden_size, hidden_size))
- layers.append(nn.ReLU())
- layers.append(nn.BatchNorm1d(hidden_size))
- layers.append(nn.Dropout(0.3))
- self.inLayer = nn.Linear(input_size, hidden_size)
- self.relu = nn.ReLU()
- self.hiddenLayer = nn.Sequential(*layers)
- self.outLayer = nn.Linear(hidden_size, num_classes)
- self.softmax = nn.Softmax(dim=1)
- def forward(self, x):
- out = self.inLayer(x)
- out = self.relu(out)
- out = self.hiddenLayer(out)
- out = self.outLayer(out)
- out = self.softmax(out)
- return out
接着对上面的网络进行初始化.
- input_size = 4
- hidden_size = 20
- num_classes = 3
- n_layers = 1
- # 网络初始化
- model = NeuralNet(input_size, hidden_size, num_classes, n_layers)
- print(model)

网络的训练
接下来就是对网络的训练, 这里我就把所有的内容都写在一起了. 主要可以分为下面的几个部分.
- 定义损失函数和优化函数
- 训练模型
- 验证模型
- # 模型的训练
- num_epochs = 30
- learning_rate = 0.001
- # ------------------
- # Loss and optimizer
- # ------------------
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
- # ---------------
- # Train the model
- # ---------------
- model.train()
- total_step = len(train_loader)
- for epoch in range(num_epochs):
- for i, (data, labels) in enumerate(train_loader):
- # Move tensors to the configured device
- # images = images.reshape(-1, 28*28).to(device)
- # labels = labels.to(device)
- # Forward pass
- outputs = model(data)
- loss = criterion(outputs, labels)
- # Backward and optimize
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- if (i+1) % 5 == 0:
- # 计算每个batch的准确率
- correct = 0
- total = 0
- _, predicted = torch.max(outputs.data, 1)
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- acc = 100*correct/total
- # 打印结果
- print ('Epoch [{}/{}], Step [{}/{}], Accuracy: {}, Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, acc, loss.item()))
- # -----------------------------------
- # Test the model(每一个epoch打印一次)
- # -----------------------------------
- # In test phase, we don't need to compute gradients (for memory efficiency)
- model.eval()
- with torch.no_grad():
- correct = 0
- total = 0
- for data, labels in test_loader:
- # images = images.reshape(-1, 28*28).to(device)
- # labels = labels.to(device)
- outputs = model(data)
- _, predicted = torch.max(outputs.data, 1)
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- print('Accuracy of the network test dataset: {} %'.format(100 * correct / total))
- print('-'*10)

到这里就完成了一个大致的使用Pytorch进行训练的完整的例子. 下面是使用LIME的一些说明.
使用LIME解释Pytorch构建的模型
使用LIME来解释Pytorch的模型主要有下面的几个步骤:
- 定义预测函数
- 创建解释器
- 对某一个样本给出解释
首先定义预测函数
- # 定义预测函数
- def batch_predict(data, model=model):
- """
- model: pytorch训练的模型, **这里需要有默认的模型**
- data: 需要预测的数据
- """
- X_tensor = torch.from_numpy(data).float()
- model.eval()
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- model.to(device)
- X_tensor = X_tensor.to(device)
- logits = model(X_tensor)
- probs = torch.nn.functional.softmax(logits, dim=1)
- return probs.detach().cpu().numpy()
我们定义成这个样子是因为最后需要输入到LIME中去, 他去要接受这样的函数. 我们可以简单测试一下上面的函数, 输入数据, 出来的是每一类的概率.
- # 测试一下上面的函数
- test_Data = x[:10]
- prob = batch_predict(data=test_Data, model=model)
- print(prob)
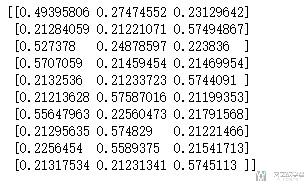
创建解释器
接着我们创建一个解释器, 用来对后面的样本进行解释.
- # 创建解释器
- targets = ['Iris-versicolor', 'Iris-virginica', 'Iris-setosa']
- features_names=['sepal length','sepal width','petal length','petal width']
- explainer = lime.lime_tabular.LimeTabularExplainer(x,
- feature_names=features_names,
- class_names=targets,
- discretize_continuous=True)
解释某一个样本
- # 解释某一个样本
- exp = explainer.explain_instance(x[5],
- batch_predict,
- num_features=5,
- top_labels=5)
在这里我们是对第5个样本进行解释.
结果可视化
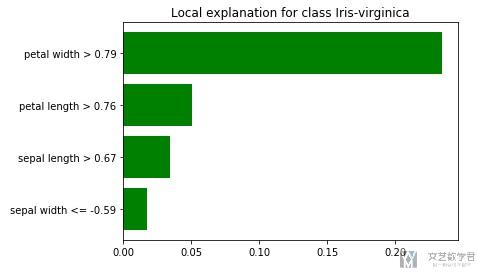
最后一步就是结果的可视化. 这里可视化的内容会包括是某一类的原因(或是不是某一类的原因), 比如对于Iris dataset来说, 会分别给出三张图. 我们看下面的结果的表示.
- # 结果的展示
- exp.show_in_notebook(show_table=True, show_all=False)
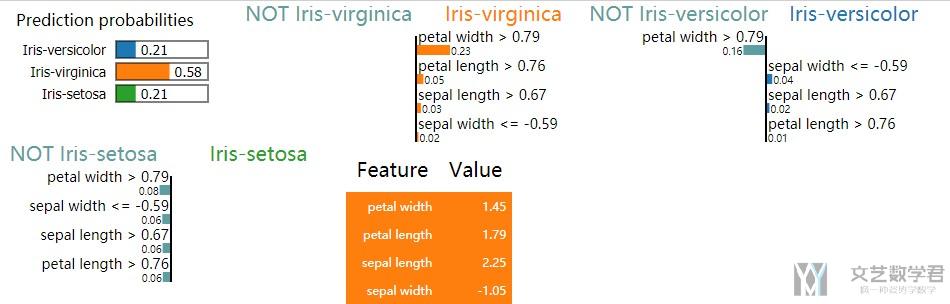
如上图所示, 对于Iris-virginica来说, 她给出了是这个分类的原因, 例如因为petal width>0.79, 这就是给出了一个模型判断的原因.
出了上面的画图方式, 我们还可以使用下面的画图方式, 只画出某一个类别的判断的可能性.
- exp.as_pyplot_figure(label=1)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论