文章目录(Table of Contents)
简介
这一部分介绍使用LIME来进行模型解释. LIME的全程为Local Interpretable Model-agnostic Explanations. 在这一部分我们会介绍LIME方法的主要的思想, 和结合Pytorch来进行解释, 解释使用Pytorch搭建的模型. 下面是一些LIME的参考资料.
之前我们也讲过一个模型解释的方法, 叫做Saliency Map, 之前的链接如下: Saliency Maps的原理与简单实现(使用Pytorch实现)
参考资料
- 模型的可解释性书本的一章: 5.7 Local Surrogate (LIME)
- 原始论文: Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why should I trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM (2016).
- Python的库LIME: Lime: Explaining the predictions of any machine learning classifier
LIME的原理
LIME的想法很简单, 我们希望使用简单的模型来对复杂的模型进行解释. 这里简单的模型可以是线性模型, 因为我们可以通过查看线性模型的系数大小来对模型进行解释. 在这里, LIME只会对每一个样本进行解释(explain individual predictions).
LIME会产生一个新的数据集(这个数据集我们是通过对某一个样本数据进行变换得到), 接着在这个新的数据集上, 我们训练一个简单模型(容易解释的模型), 我们希望简答模型在新数据集上的预测结果和复杂模型在该数据集上的预测结果是相似的. 我们可以将我们的问题表达为下面的表达式:
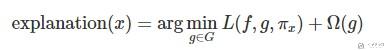
上式中每一个字母的含义:
- f表示原始的模型, 即需要解释的模型.
- g表示简单模型, G是简单模型的一个集合, 如所有可能的线性模型.
- Pi_x表示我们新数据集中的数据x'与原始数据instance x的距离.
- Ω(g)表示模型g的复杂程度.
我们希望原始模型f与新模型g预测值之间的误差是小的. 简单来说, 我们可以通过下面的式子来衡量两个式子预测值之间的差:
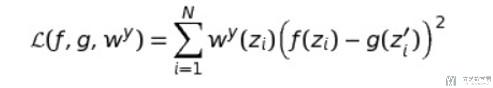
于是整个LIME的步骤如下(即训练模型g的步骤)
- 选择我们想要解释的变量x.
- 对数据集中的数据进行扰动得到新的数据, 同时计算出黑盒模型对这些新的数据的预测值.
- 对这些新的sample求出权重, 这个权重是这些数据点与我们要解释的数据之间的距离.
- 根据上面新的数据集, 预测值和权重, 训练出模型g
- 通过模型g来对模型f在x点附近进行解释.
那么我们如何对数据集进行扰动来得到新的数据, 对于表格数据, 我们可以分别扰动每一个特征, 从一个正态分布(均值和方差为这个特征的均值和方差)中进行随机抽样. 这样做会有一个问题, 即不是从我们要解释的数据为中心进行采样, 而是从整个数据集的中心进行采样. (LIME samples are not taken around the instance of interest, but from the training data's mass center, which is problematic.)
下面我们通过一张图片来对上面的过程进行解释(这张图片是上面第一个参考链接中的).
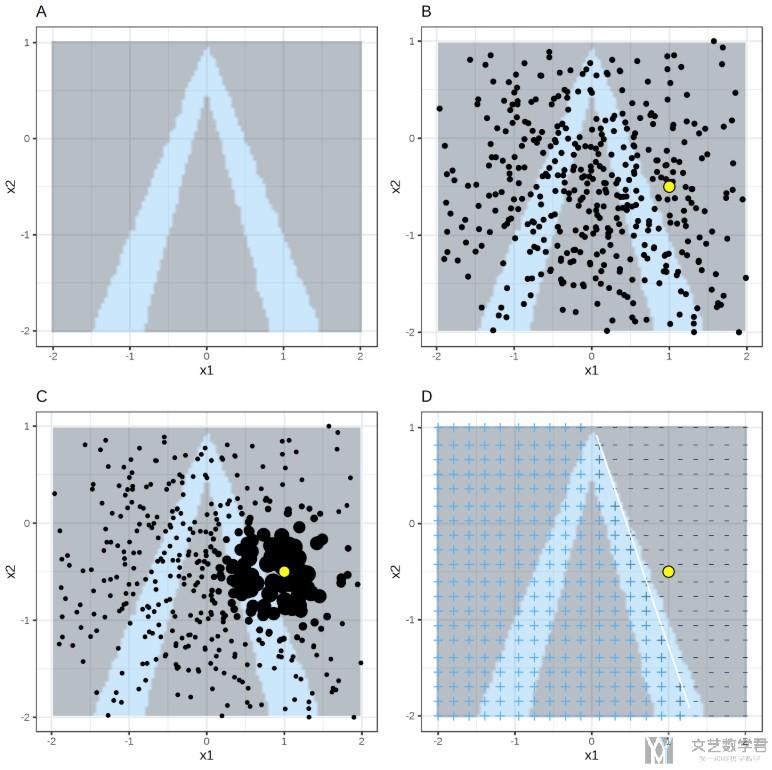
- 图A表示: 随机森林的分类结果, 颜色深的为一类, 颜色浅的为一类.
- 图B表示: 通过对特征进行扰动得到的新的数据集.
- 图C表示: 对每一个数据进行加权.
- 图D表示: 对简单的模型进行求解.
存在的问题: 定义我们要解释的点的周围是困难的.
对Pytorch搭建的模型进行解释
这一部分我们会看一下如何使用LIME来对Pytorch搭建的模型进行解释. 我们会使用库LIME来完成相关的模型的解释: Lime: Explaining the predictions of any machine learning classifier
这是一个LIME和Pytorch结合的例子: Using Lime with Pytorch. 这是一个解释图片的例子, 我们下面看一个解释表格数据的例子(我们就只看一下解释的步骤, 前面模型的训练和数据的处理就不放了).
我在GIthub上上传了一个LIME与Pytorch结合使用的例子, 链接为: Github-LIME与Pytorch结合
对于这个例子的理解, 可以参考文章: Pytorch例子演示及LIME使用例子
加载数据集和模型
这一部分在这里不是很重要, 就不详细进行说明了. 我们使用Pytorch训练好的模型叫fullModel, 导入的数据集为XData和YData.
定义预测函数
我们需要定义一个函数, 输入的是模型和x, 输出的是预测的概率.
- # 定义分类器
- def batch_predict(data, model=fullModel):
- """
- model: pytorch训练的模型
- data: 需要预测的数据
- """
- X_tensor = torch.from_numpy(data).float()
- model.eval()
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- model.to(device)
- X_tensor = X_tensor.to(device)
- logits = model(X_tensor)
- probs = F.softmax(logits, dim=1)
- return probs.detach().cpu().numpy()
上面函数的效果就是输入数据和模型, 输出的为每一个分类的概率, 下面看一下他的输出.
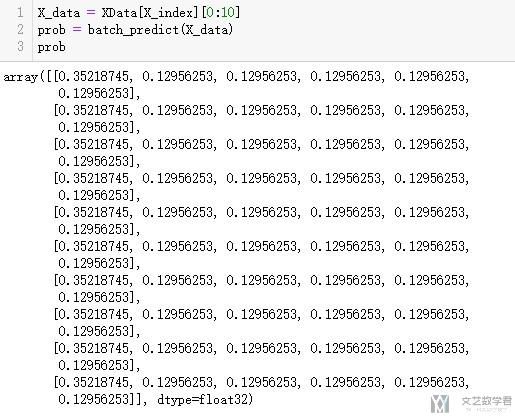
对数据进行解释
接着我们就是对我们的黑盒模型局部进行解释.
- # 创建解释器
- import lime
- import lime.lime_tabular
我们需要创建模型的输入和输出.
- X_tensor = torch.from_numpy(XData[X_index]).float()
- y_tensor = torch.from_numpy(np.array(y)).long()
接着创建解释器. 下面的feature_names就是每一个feature的名字.
- targets = ['back', 'land', 'neptune', 'pod', 'smurf', 'teardrop']
- explainer = lime.lime_tabular.LimeTabularExplainer(XData[X_index],
- feature_names=dfDataTrain.columns[:-4].values,
- class_names=targets,
- discretize_continuous=True)
最后我们对一个样本进行解释, 下面我们解释的是第505个样本.
- # 解释某一个样本
- exp = explainer.explain_instance(XData[X_index][505],
- batch_predict,
- num_features=5,
- top_labels=5)
最后我们将解释的结果显示出来.
- exp.show_in_notebook(show_table=True, show_all=False)

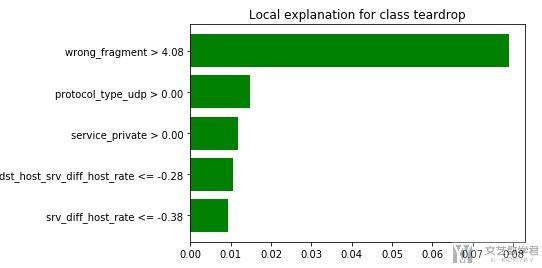
因为这是一个多分类的问题, 我们可以显示预测为某一个分类的原因.
- exp.as_pyplot_figure(label=5)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论