文章目录(Table of Contents)
简介
这里介绍一个新的强化学习的环境, Windy Gridworld Playground. 之前我们讲过Reinforcement Learning(强化学习)-BlackJack环境介绍. 但是因为我们并不知道blackJack的最优策略是什么, 所以有的时候我们无法判断最后给出的结果的好坏, 于是这里介绍一个新的环境, Windy Gridworld Playground.
参考资料
可以查看下面的链接, 里面有详细的notebook (在第5周的内容里面): 强化学习_Windy Gridworld Playground环境测试
Windy Gridworld Playground环境介绍
总的一个环境如下所示, 我们从S出发, 要达到G. 有上下左右四个方向可以走. 下面格子0, 1, 2表示风力, 也就是我们在不同的列会受到风力的影响, 导致实际的方向和我们走的会有一些区别.
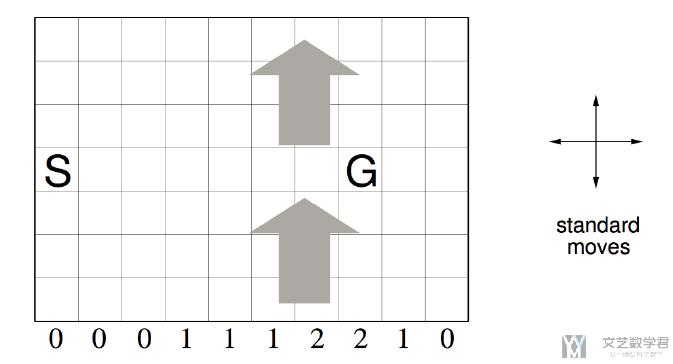
详细的每个格子的编号如下图所示:
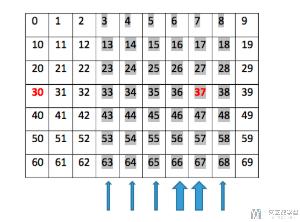
下面是文字版, 可以方便复制, 也是方格的序号的对应关系.
- 00, 01, 02, 03, 04, 05, 06, 07, 08, 09
- 10, 11, 12, 13, 14, 15, 16, 17, 18, 19
- 20, 21, 22, 23, 24, 25, 26, 27, 28, 29
- 30, 31, 32, 33, 34, 35, 36, 37, 38, 39
- 40, 41, 42, 43, 44, 45, 46, 47, 48, 49
- 50, 51, 52, 53, 54, 55, 56, 57, 58, 59
- 60, 61, 62, 63, 64, 65, 66, 67, 68, 69
详细介绍observation, action和reward
接下来我们详细介绍observation, action和reward:
- observation为格子所在的编号, 起始的编号是30;
- action的组成: 有4个动作, 分别是上下左右, 数字与action的对应关系如下;
- 0, UP
- 1, RIGHT
- 2, DOWN
- 3, LEFT
- reward: 每走一步reward=-1, reward越大也就是走的步数越少;
仿真的部分代码
首先是环境的初始化.
- state = environment.reset()
- print(state) # 返回的是格子的编号(30也是起点的位置)
- >> 30 # 从状态30开始, 是起点
我们可以通过下面的方式进行可视化.
- # 结果可视化
- environment._render()

其中x表示现在所在的位置, T表示终点.
接着我们可以执行不同的action, 并查看返回的结果.
- observation, reward, done, _ = environment.step(0)
- print("observation:{}, reward:{}, done:{}".format(observation, reward, done))
- >> observation:20, reward:-1.0, done:False
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论