文章目录(Table of Contents)
简介
在前面的例子中, 我们介绍了在Pytorch中的损失函数和优化器的使用. 但是还有一个可以改进的地方. 在前面的函数的定义中, 我们使用了forward函数, 自己定义了y=w*x. 但是实际上, Pytorch也是提供了模型的定义, 对于这种线性模型, 我们可以直接使用nn.Linear来进行定义.
在这一部分, 我们会首先说明使用Pytorch进行模型的定义, 再给出一个完整的线性回归的例子. 因为这一部分和之前的比较类似, 下面代码给出主要代码, 完整代码在github仓库中查看.
Github仓库链接: 简单线性回归
完整的线性回归例子
模型的建立
这里我们需要建立线性模型, 我们直接使用pytorch中的nn.Linear来完成模型的创建.
- class LinearRegression(nn.Module):
- def __init__(self):
- super(LinearRegression, self).__init__()
- self.linear1 = nn.Linear(1, 1)
- def forward(self, x):
- x = self.linear1(x)
- return x
在上面的自定义模型中, 有以下几个需要注意的点:
- 自定的神经网络类必须继承
nn.Module. - 自定义类中需要实现
__init__和forward函数. __init__: 定义网络的结构.forward: 定义数据在模型中的传播路径.
接着我们初始化模型.
- # 模型初始化
- linearModel = LinearRegression()
定义损失函数和优化器
损失函数的定义和之前没有什么区别.
- loss = torch.nn.MSELoss() # 定义均方损失函数
在定义优化器时, 直接利用model.parameters()表示模型中所有需要求的权重. 这里主要就是参数传入的时候的区别, 其他的都是一样的.
- # 定义一个SGD优化器
- learning_rate = 0.001
- optimizer = torch.optim.SGD(linearModel.parameters(), lr=learning_rate)
模型的训练
最后一个步骤就是模型的训练. 这里有一个需要注意的是, 数据需要转换为2维的(这个是很重要的). 这里是100*1的大小, 表示有100个样本, 每一个样本是1维.
- X_tensor = torch.from_numpy(X).view(100,1)
- Y_tensor = torch.from_numpy(Y).view(100,1)
最后还是按照之前的步骤训练即可.
- n_iters = 101
- for epoch in range(n_iters):
- y_pred = linearModel(X_tensor)
- l = loss(Y_tensor, y_pred) # 求误差(注意这里的顺序)
- l.backward() # 求梯度
- optimizer.step() # 更新权重,即向梯度方向走一步
- optimizer.zero_grad() # 清空梯度
- [w, b] = linearModel.parameters() # 获得参数
- if epoch % 20 == 0:
- print(f'epoch {epoch+1}: w = {w.data}, loss = {l.item():.3f}')
- print(f'根据训练模型预测, 当x=5时, y的值为: {linearModel(torch.tensor([5.0]))}')
- """
- epoch 1: w = tensor([[0.8991]]), loss = 49.043
- epoch 21: w = tensor([[1.7334]]), loss = 3.314
- epoch 41: w = tensor([[1.9409]]), loss = 0.481
- epoch 61: w = tensor([[1.9924]]), loss = 0.305
- epoch 81: w = tensor([[2.0050]]), loss = 0.294
- epoch 101: w = tensor([[2.0080]]), loss = 0.294
- 根据训练模型预测, 当x=5时, y的值为: tensor([10.9290], grad_fn=<AddBackward0>)
- """
可以看到参数w正在逐渐朝2逼近.
结果可视化
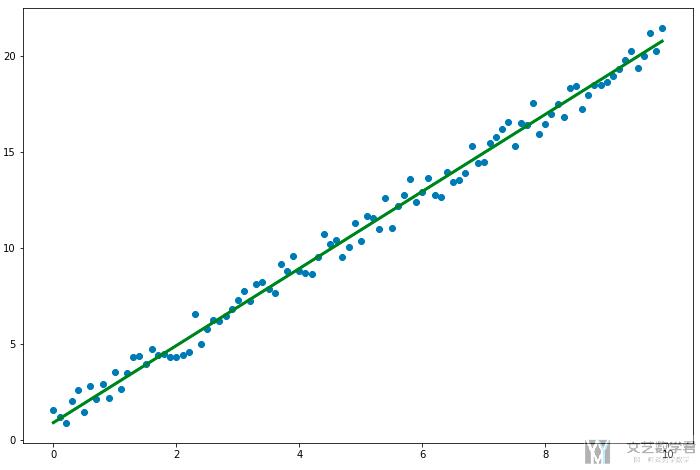
最后, 我们将拟合出来的直线绘制出来即可.
- # 绘制预测曲线
- y_pre = linearModel(X_tensor).detach().numpy()
- fig = plt.figure(figsize=(12,8))
- ax = fig.add_subplot(1,1,1)
- ax.scatter(X,Y)
- ax.plot(X, y_pre, 'g-', lw=3)
- fig.show()
最终的结果如下所示:
Pytorch训练步骤总结
下面是使用Pytorch进行训练的一个完整的步骤:
- 利用
model(X)进行正向传播。 - 利用
loss(Y, y_predicted)计算模型损失。 - 利用
loss.backward()计算模型梯度。 - 利用
optimizer.step()更新权重。 - 利用
optimizer.zero_grad()清空梯度。 - 重复 1-5 的操作。
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论