文章目录(Table of Contents)
简介
前面我们介绍了正向传播, 反向传播, 梯度下降法. 也介绍了Pytorch中的损失函数和优化器, 数据加载器, 数据预处理, 和交叉熵. 这一篇, 我们使用之前学习到的所有知识, 建立一个全连接的神经网络, 来完成手写字符的识别.
之前我曾经写过一个版本的使用Pytorch实现手写字符的识别, 当时主要目的是为了实现如何动态修改网络结构, 所以总的结构不是很完整, 这一篇会写的比较完整. 上一个版本的链接: Pytorch模型实例-MNIST dataset
这一部分的代码, 见github链接: 全连接网络的手写数字识别(MNIST).ipynb
全连接网络完成手写数字识别
准备工作
在准备工作阶段, 我们需要导入需要的库, 并且判断实验环境是否支持GPU, 还是只能使用CPU.
- import torch
- import torch.nn as nn
- import torchvision
- import torchvision.transforms as transforms
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- # Device configuration
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- device
数据加载与数据预处理
我们使用MNIST数据集, 该数据集可以使用torchvision.datasets.MNIST获得. 这一阶段的任务如下所示:
- 创建dataset
- 加载MNIST数据
- 进行数据预处理, 转换为tensor
- 创建dataloader
- 将dataset传入dataloader, 设置batchsize
首先我们创建dataset, 同时设置数据预处理.
- # 将数据集合下载到指定目录下,这里的transform表示,数据加载时所需要做的预处理操作
- # 加载训练集合(Train)
- train_dataset = torchvision.datasets.MNIST(root='./data',
- train=True,
- transform=torchvision.transforms.ToTensor(),
- download=True)
- # 加载测试集合(Test)
- test_dataset = torchvision.datasets.MNIST(root='./data',
- train=False,
- transform=transforms.ToTensor())
- print(train_dataset) # 训练集
- """
- Dataset MNIST
- Number of datapoints: 60000
- Root location: ./data
- Split: Train
- StandardTransform
- Transform: ToTensor()
- """
- print(test_dataset) # 测试集
- """
- Dataset MNIST
- Number of datapoints: 10000
- Root location: ./data
- Split: Test
- StandardTransform
- Transform: ToTensor()
- """
接着设置dataloader, 设置batchsize的大小. 这里的dataloader就是训练的时候会用到的.
- batch_size = 100
- # 根据数据集定义数据加载器
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=batch_size,
- shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=False)
最后查看一下样例数据(样例图像), 注意如何查看dataloader中的数据:
- # 查看数据
- examples = iter(test_loader)
- example_data, example_target = examples.next() # 100*1*28*28
- for i in range(9):
- plt.subplot(3,3,i+1).set_title(example_target[i])
- plt.imshow(example_data[i][0], 'gray')
- plt.tight_layout()
- plt.show()

网络的构建
我们定义一个三层的网络, 网络大小分别是(784, 500, 10), 网络定义如下所示:
- # 输入节点数就为图片的大小:28×28×1
- input_size = 784
- # 由于数字为 0-9,因此是10分类问题,因此输出节点数为 10
- num_classes = 10
- # 网络的建立
- class NeuralNet(nn.Module):
- # 输入数据的维度,中间层的节点数,输出数据的维度
- def __init__(self, input_size, hidden_size, num_classes):
- super(NeuralNet, self).__init__()
- self.input_size = input_size
- self.l1 = nn.Linear(input_size, hidden_size)
- self.relu = nn.ReLU()
- self.l2 = nn.Linear(hidden_size, num_classes)
- def forward(self, x):
- out = self.relu(self.l1(x))
- out = self.l2(out)
- return out
- model = NeuralNet(input_size, 500, num_classes).to(device)
- model
- """
- NeuralNet(
- (l1): Linear(in_features=784, out_features=500, bias=True)
- (relu): ReLU()
- (l2): Linear(in_features=500, out_features=10, bias=True)
- )
- """
我们用dataloader中的数据测试一下网络, 是否可以正常运算.
- # 简单测试模型的输出
- examples = iter(test_loader)
- example_data, _ = examples.next() # 100*1*28*28
- model(example_data.reshape(example_data.size(0),-1)).shape
- """
- torch.Size([100, 10])
- """
为了更加详细的了解网络的构造, 我们可以构造一个测试样例, 并打印出每一层的输出大小.
- X = torch.randn(1, 1, 224, 224)
- for layer in net:
- X=layer(X)
- print(layer.__class__.__name__,'Output shape:\t',X.shape)
定义损失函数和优化器
接下来, 我们定义损失函数和优化器.
- # 定义学习率
- learning_rate = 0.001
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
模型的训练与测试
有了上面的铺垫之后, 我们就可以开始模型的训练和测试了. 我们定义需要的epoch的数量, 同时保存每一个epoch的loss和在测试集上的准确率.
下面的代码有几个注意的点:
- loss不是每一次的loss, 而是会计算整个epoch的平均loss
- 每一个epoch结束之后在测试集上进行测试, 保存测试的准确率
- num_epochs = 10
- n_total_steps = len(train_loader)
- LossList = [] # 记录每一个epoch的loss
- AccuryList = [] # 每一个epoch的accury
- for epoch in range(num_epochs):
- # -------
- # 开始训练
- # -------
- model.train() # 切换为训练模型
- totalLoss = 0
- for i, (images, labels) in enumerate(train_loader):
- images = images.reshape(-1, 28*28).to(device) # 图片大小转换
- labels = labels.to(device)
- # 正向传播以及损失的求取
- outputs = model(images)
- loss = criterion(outputs, labels)
- totalLoss = totalLoss + loss.item()
- # 反向传播
- optimizer.zero_grad() # 梯度清空
- loss.backward() # 反向传播
- optimizer.step() # 权重更新
- if (i+1) % 300 == 0:
- print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, n_total_steps, totalLoss/(i+1)))
- LossList.append(totalLoss/(i+1))
- # ---------
- # 开始测试
- # ---------
- model.eval()
- with torch.no_grad():
- correct = 0
- total = 0
- for images, labels in test_loader:
- images = images.reshape(-1, 28*28).to(device)
- labels = labels.to(device)
- outputs = model(images)
- _, predicted = torch.max(outputs.data, 1) # 预测的结果
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- acc = 100.0 * correct / total # 在测试集上总的准确率
- AccuryList.append(acc)
- print('Accuracy of the network on the {} test images: {} %'.format(total, acc))
- print("模型训练完成")
- """
- Epoch [9/10], Step [300/600], Loss: 0.0112
- Epoch [9/10], Step [600/600], Loss: 0.0133
- Accuracy of the network on the 10000 test images: 98.03 %
- Epoch [10/10], Step [300/600], Loss: 0.0092
- Epoch [10/10], Step [600/600], Loss: 0.0114
- Accuracy of the network on the 10000 test images: 98.08 %
- 模型训练完成
- """
接着我们绘制一下loss和accuracy的变化趋势. 首先查看loss的变化趋势.
- # 绘制loss的变化
- fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(13,7))
- axes.plot(LossList, 'k--')
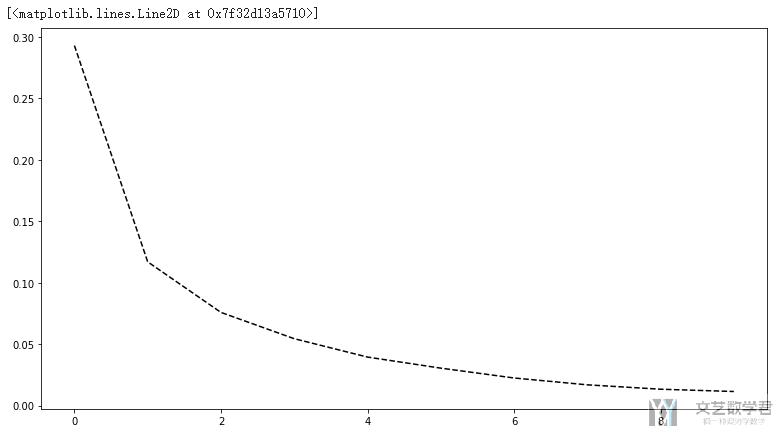
接着查看accuracy的变化趋势:
- # 绘制loss的变化
- fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(13,7))
- axes.plot(AccuryList, 'k--')
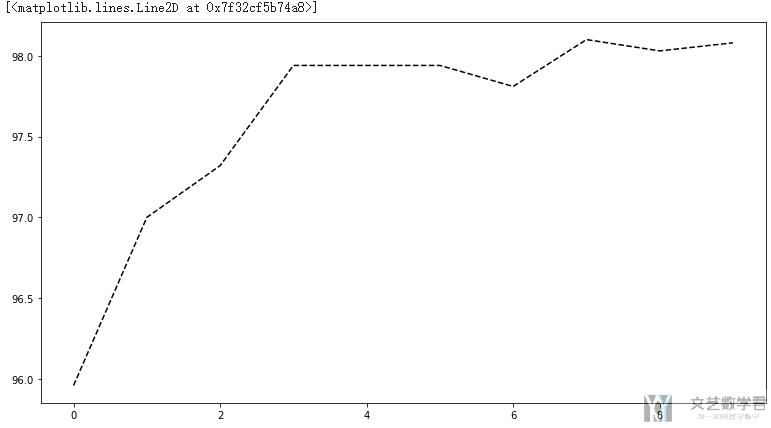
查看测试集上预测结果
最后, 我们从测试集中找几个例子来看一下实际的测试结果.
- # 测试样例
- examples = iter(test_loader)
- example_data, example_targets = examples.next()
- # 实际图片
- for i in range(9):
- plt.subplot(3, 3, i+1)
- plt.imshow(example_data[i][0], cmap='gray')
- plt.show()
- # 结果的预测
- images = example_data.reshape(-1, 28*28).to(device)
- labels = example_targets.to(device)
- # 正向传播以及损失的求取
- outputs = model(images)
- # 将 Tensor 类型的变量 example_targets 转为 numpy 类型的,方便展示
- print("上面三张图片的真实结果:", example_targets[0:9].detach().numpy())
- # 将得到预测结果
- # 由于预测结果是 N×10 的矩阵,因此利用 np.argmax 函数取每行最大的那个值,最为预测值
- print("上面三张图片的预测结果:", np.argmax(outputs[0:9].detach().numpy(), axis=1))
最终的结果如下, 可以看到前9个数字的预测都是准确的.

- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论