文章目录(Table of Contents)
简介
PyTorch 中的所有操作都是在张量的基础上进行的。作为 Pytorch 的一份入门的资料,我们就会首先从张量开始讲起,主要分为下面几个部分:
- 张量的定义;
- 张量的运算;
- 张量的切片;
- 改变张量形状;
- GPU 还是 CPU;
在所有操作开始之前,我们首先导入 Pytorch 库:
- import torch
张量的简单介绍
PyTorch 中的所有内容都基于 Tensor 操作。我们可以使用 empty 来创建一维、二维、或是三维的张量。在这里我们会介绍一下几种初始化张量的方式:
- 一维张量(Scalars),利用 item 转换为 python float 类型
- 张量的创建
- 创建空张量, torch.empty.
- 创建随机张量, torch.rand或torch.randn.
- 创建全0或全1张量, torch.zeros和torch.ones
- 创建指定值的张量, torch.tensor(List)
- Numpy与Tensor的相互转化(比较常用)
- 张量的类型, 使用 dtype 查看或指定张量的类型
- 张量是否自动计算梯度,
requires_grad=True进行指定.
一维张量(Scalars)
在 Pytorch 中,我们可以创建只包含一个元素的 tensor 作为 scalar。下面是一个简单的例子,对 scalar 进行运算:
- x = torch.tensor([3.0])
- y = torch.tensor([2.0])
- print('x + y = ', x + y)
- print('x * y = ', x * y)
- print('x / y = ', x / y)
- print('x ** y = ', torch.pow(x,y))
- """
- x + y = tensor([5.])
- x * y = tensor([6.])
- x / y = tensor([1.5000])
- x ** y = tensor([9.])
- """
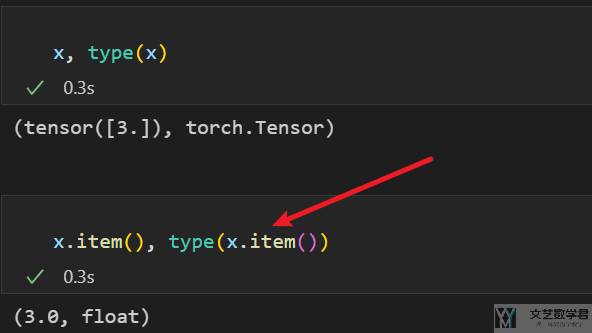
对于 scalar 来说,我们可以使用 item 转换为 python float 类型。如下图所示,x 本来是 torch.Tensor,使用 item 之后转换为 float(常用于对 loss 的处理)
张量的创建
torch.empty可以初始化指定大小的张量, 如果不指定值的话, 内容为随机值. (注意, 我们可以通过x.size查看张量的大小)
- x = torch.empty(2)
- print(x.size())
- # >> torch.Size([2])
- x = torch.empty(2,3)
- print(x.size())
- # >> torch.Size([2, 3])
- x = torch.empty(1,2,3)
- print(x.size())
- # >> torch.Size([1, 2, 3])
我们也可以使用torch.rand来进行初始化, 他可以生成0-1之间的向量(服从uniform distribution). 使用torch.randn可以生成服从N(0,1)的数据.
下面我们生成 2*3 的随机向量:
- torch.rand(2,3)
- """
- tensor([[0.1180, 0.6572, 0.6190],
- [0.9897, 0.8449, 0.1371]])
- """
如果想要初始化全 0 或是全 1 的张量,可以使用torch.zeros(size) 和 torch.ones(size)来完成。
- x = torch.zeros(2, 2) # 全0张量
- print(x)
- """
- tensor([[0., 0.],
- [0., 0.]])
- """
- y = torch.ones(2, 2) # 全1张量
- print(y)
- """
- tensor([[1., 1.],
- [1., 1.]])
- """
除了上面的方法之外, 我们还可以创建指定值的张量, 我们使用 torch.tensor(list),
- x = torch.tensor([[1,2],[3,4]])
- print(x)
- """
- tensor([[1, 2],
- [3, 4]])
- """
还有一种比较常用的做法是, 将 numpy 转换为 tensor。这两个数据类型之间是可以相互转换的。我们看下面一个简单的例子:
- # numpy -> tensor
- x = np.ones((2,3))
- y = torch.from_numpy(x)
- print(y)
- """
- tensor([[1., 1., 1.],
- [1., 1., 1.]], dtype=torch.float64)
- """
- # tensor -> numpy
- x = torch.zeros(2,3)
- y = x.numpy()
- print(type(y))
- # <class 'numpy.ndarray'>
有的时候, 我们需要指定更加详细的数据类型, 我们可以在numpy的时候就进行定义, 下面是一个简单的例子. 下面我们将特征数据定义为float32类型, label数据定义为long类型.
- # 特征数据
- X_train = torch.from_numpy(X_train.astype(np.float32))
- X_test = torch.from_numpy(X_test.astype(np.float32))
- # 标签数据
- y_train = torch.from_numpy(y_train.astype(np.long))
- y_test = torch.from_numpy(y_test.astype(np.long))
张量的类型
上面是介绍了张量定义的方法, 除此之外, 我们还可以使用x.dtype查看tensor的具体类型.
- x = torch.rand(2,2)
- print(x.dtype)
- # torch.float32
同样的, 我们在定义张量的时候, 也是可以指定他的类型的.
- x = torch.rand(2, 2, dtype=torch.float64)
- print(x)
- """
- tensor([[0.0942, 0.6157],
- [0.6045, 0.1863]], dtype=torch.float64)
- """
- # check type
- print(x.dtype)
- # torch.float64
指定张量是否计算梯度
除此之外, 我们在定义张量的时候, 需要指定他是否可以计算梯度, 需要设置参数 requires_grad.
- x = torch.tensor([[1,2],[3,4]], dtype=torch.float32, requires_grad=True)
- print(x)
- """
- tensor([[1., 2.],
- [3., 4.]], requires_grad=True)
- """
张量的运算
基础运算
张量的运算包括张量的加法(+), 减法(-), 乘法(*)和除法(/)。我们就可以直接使用常见的符号来进行运算。同时,也可以使用 torch 中的函数来完成,下面简单看一下例子(这些运算都是 element-wise operations,也就是每个元素分别计算):
- x = torch.ones(2,2)
- y = torch.ones(2,2)
- # 加法
- z = torch.add(x,y)
- print(z)
- """
- tensor([[2., 2.],
- [2., 2.]])
- """
- # 减法
- z = torch.sub(x, y)
- print(z)
- """
- tensor([[0., 0.],
- [0., 0.]])
- """
- # 乘法
- z = torch.mul(x, y)
- print(z)
- """
- tensor([[1., 1.],
- [1., 1.]])
- """
- # 除法
- z = torch.div(x, y)
- print(z)
- """
- tensor([[1., 1.],
- [1., 1.]])
- """
向量乘法-dot product
在上面的例子在,我们的运算都是分别对每个元素进行计算。但是还有一个比较常用的就是 dot product。例如现在有两个向量 u 和 v(这里默认向量都是竖着的),要求这两个向量的乘法,则计算式子如下所示:
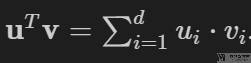
我们可以使用 torch.dot 来完成 dot product,下面是一个简单的例子:
- x = torch.arange(4, dtype = torch.float32)
- y = torch.ones(4, dtype = torch.float32)
- print(x, y, torch.dot(x, y))
- """
- tensor([0., 1., 2., 3.]) tensor([1., 1., 1., 1.]) tensor(6.)
- """
矩阵向量乘法-torch.mv
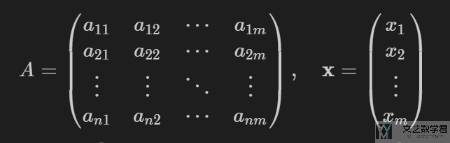
现在假设有一个矩阵 A 和一个向量 x 如下所示,我们对其相乘。
其中矩阵 A 可以使用下面的方式进行表示,其中 a.T 表示矩阵 A 的一行:
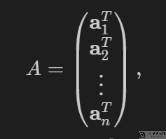
于是矩阵与向量的乘法可以转换为向量与向量的乘法,如下所示:
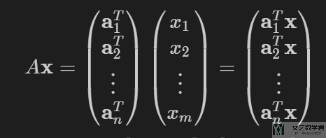
我们使用 tensor.mv() 来进行矩阵与向量相乘。例如 torch.mv(A, x) 就表示矩阵 A 与向量 x 相乘。下面看一个具体的例子,矩阵 A 的大小为 5×4,向量 x 的大小为 4×1,最终的结果为 5×1:
- A = torch.arange(20, dtype=torch.float32).reshape((5,4))
- x = torch.arange(4, dtype = torch.float32)
- torch.mv(A, x)
- """
- tensor([ 14., 38., 62., 86., 110.])
- """
矩阵与矩阵乘法-torch.mm
最后来看一下矩阵的乘法。矩阵 A 和矩阵 B 相乘。同样将矩阵转换为向量表示,如下所示:
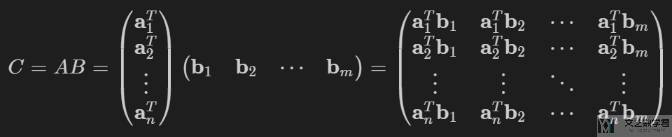
我们使用 torch.mm 进行矩阵乘法。下面是一个具体的例子:
- A = torch.arange(20, dtype=torch.float32).reshape((5,4))
- B = torch.ones(size=(4, 3))
- torch.mm(A, B)
- """
- tensor([[ 6., 6., 6.],
- [22., 22., 22.],
- [38., 38., 38.],
- [54., 54., 54.],
- [70., 70., 70.]])
- """
Batch 的矩阵乘法-torch.bmm
下面我们看一下在 Pytorch 中如何进行 batch 矩阵乘法。我们测试的矩阵乘法如下所示,我们简单说明一下,下面是 2x1x3,2x3x1,得到的结果是2x1x1。这个也就是在 batch 内部,还是在进行矩阵乘法。
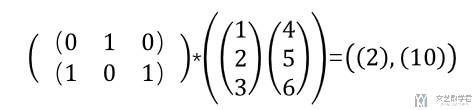
我们使用 Pytorch 做以下测试,可以看到结果是和我们自己计算是一样的。
- # torch.bmm测试-这是矩阵乘法
- x_test = torch.tensor([[[0,1,0]],[[1,0,1]]])
- y_test = torch.tensor([[[1],[2],[3]],[[4],[5],[6]]])
- print(x_test.shape,y_test.shape)
- print(torch.bmm(x_test,y_test))
- """
- torch.Size([2, 1, 3]) torch.Size([2, 3, 1])
- tensor([[[ 2]],
- [[10]]])
- """
参考资料: torch.bmm官方文档
按行按列求和
除了完成上面的简单的加减乘除的运算,我们还可以完成一些整体的运算。例如我们可以对 tensor 进行求和运算。下面我们按列进行求和:
- X = torch.tensor([[1., 2., 3.], [4., 5., 6.]])
- torch.sum(X, dim=1)
- """
- tensor([ 6., 15.])
- """
我们也可以保持维度,按列求和的时候,就是将一行的元素全部加起来,最后应该是 2*1 的大小。我们可以使用 keepdim 来实现求和前后维度的相同:
- X = torch.tensor([[1., 2., 3.], [4., 5., 6.]])
- torch.sum(X, dim=1, keepdim=True)
- """
- tensor([[ 6.],
- [15.]])
- """
转置运算
下面首先生成一个 4*5 的矩阵:
- A = torch.arange(20, dtype=torch.float32).reshape((5,4))
- print(A)
- """
- tensor([[ 0., 1., 2., 3.],
- [ 4., 5., 6., 7.],
- [ 8., 9., 10., 11.],
- [12., 13., 14., 15.],
- [16., 17., 18., 19.]])
- """
可以使用 A.t() 或是 A.T 对矩阵进行转置,也就是如果 B=A.T,那么会有 b(i,j)=a(j,i):
- print(A.t())
- """
- tensor([[ 0., 4., 8., 12., 16.],
- [ 1., 5., 9., 13., 17.],
- [ 2., 6., 10., 14., 18.],
- [ 3., 7., 11., 15., 19.]])
- """
张量的切片
张量的切片就与 Numpy 中的操作是一样的。我们简单看下面的一个例子:
- x = torch.rand(2, 3)
- print(x)
- print(x[1, 1]) # 表示第二行, 第二列的值. (2,2)
- print(x[:, 0]) # 第1列
- print(x[1, :]) # 第2行
- """
- tensor([[0.9756, 0.6967, 0.5652],
- [0.1255, 0.2977, 0.6983]])
- tensor(0.2977)
- tensor([0.9756, 0.1255])
- tensor([0.1255, 0.2977, 0.6983])
- """
内存节省(关于Savig Memory)
再Pytorch中, 每次我们定义一个新的变量, 系统就会指定一个新的内存. 同时他不会实时进行内存的回收. 但是在机器学习的时候, 每个时刻都会有大量的系数, 所以我们需要写的时候注意关于内存的节省. 主要有下面两个方法, 分别是:
- x[:] = expression
- x += y
例如, 像下面这样直接对z进行赋值, 是会新建一个z来进行保存的.
- z = torch.zeros_like(y)
- print('id(z):', id(z))
- z = x + y # 这样赋值会重新分配内存
- print('id(z):', id(z))
- """
- id(z): 140029165236864
- id(z): 140029165234768
- """
但是如果像下面这样, 就是不会重新进行内存的分配的.
- z = torch.zeros_like(y)
- print('id(z):', id(z))
- z[:] = x + y # 这样是不会重新分配内存的
- print('id(z):', id(z))
- """
- id(z): 140029165234848
- id(z): 140029165234848
- """
同样, 我们在进行累加的时候, 可以使用x += y的写法, 是和 x=x+y是一样的.
- print(id(x))
- print(x)
- """
- 140029165148272
- tensor([[40., 38., 44., 42.],
- [38., 40., 42., 44.],
- [32., 33., 34., 35.]])
- """
- print(y)
- """
- tensor([[14., 13., 16., 15.],
- [13., 14., 15., 16.],
- [12., 12., 12., 12.]])
- """
使用x += y的方法进行累加, 可以看到内存地址是一样的. 如果使用x=x+y, 那么x会重新进行内存的分配.
- x += y
- print(id(x))
- print(x)
- """
- 140029165148272
- tensor([[54., 51., 60., 57.],
- [51., 54., 57., 60.],
- [44., 45., 46., 47.]])
- """
转换为 One-hot 向量
在大部分时候(即使是在分类任务中),我们也是不需要转换为 one-hot 的格式的。但是我们也是可以的使用 scatter 来进行转换,例如下面的例子:
- batch_size = 5
- nb_digits = 10
- # Dummy input that HAS to be 2D for the scatter (you can use view(-1,1) if needed)
- y = torch.LongTensor(batch_size,1).random_() % nb_digits
- # One hot encoding buffer that you create out of the loop and just keep reusing
- y_onehot = torch.FloatTensor(batch_size, nb_digits)
- # In your for loop
- y_onehot.zero_()
- y_onehot.scatter_(1, y, 1)
- print(y)
- """
- tensor([[2],
- [1],
- [7],
- [4],
- [9]])
- """
- print(y_onehot)
- """
- tensor([[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
- [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
- [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
- [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
- [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])
- """
参考链接, Convert int into one-hot format
改变张量形状
使用 view 或是 reshape 修改形状
有的时候我们需要对张量的形状进行改变,可以最基础的可以使用 view 或是 reshape 进行修改。我们首先看一下使用 view 来修改张量(需要注意的是使用 view 只是改变形状,是共享内存的)。详细的可以查看链接,view方法修改tensor形状-详细说明。
下面是使用view来进行修改的一个例子:
- x = torch.randn(4, 4)
- y = x.view(1, 16) # 指定改变后的大小
- z = x.view(2, 8)
- print(x.size(), y.size(), z.size())
- # torch.Size([4, 4]) torch.Size([1, 16]) torch.Size([2, 8])
同样的内容, 我们可以使用reshape也来进行.
- x = torch.randn(4, 4)
- y = x.reshape(1, 16) # 指定改变后的大小
- z = x.reshape(2, 8)
- print(x.size(), y.size(), z.size())
- # torch.Size([4, 4]) torch.Size([1, 16]) torch.Size([2, 8])
关于view和reshape的区别在于, It means that torch.reshape may return a copy or a view of the original tensor. (也就是使用reshape可能是返回的一个copy, 而不会共享内存). 可以参考链接, What's the difference between reshape and view in pytorch?
当然, 使用view或是reshape的时候, 可以有一个维度是不指定大小的, 使用-1来代替.
- x = torch.ones(3,5,5)
- y = x.view(3,-1)
- print(y.size())
- # torch.Size([3, 25])
使用 squeeze 和 unsqueeze 添加或删除维度
squeeze 和 unsqueeze 是两个非常实用的功能,用来添加或是删除维度。下面是官方的定义:
- The
squeezemethod "returns a tensor with all the dimensions ofinputof size 1 removed", - The
unsqueeze"returns a new tensor with a dimension of size one inserted at the specified position".
简单来说 unsqueeze 可以在指定位置添加维度,squeeze 则会删除所有 1 的维度。如下图所示:
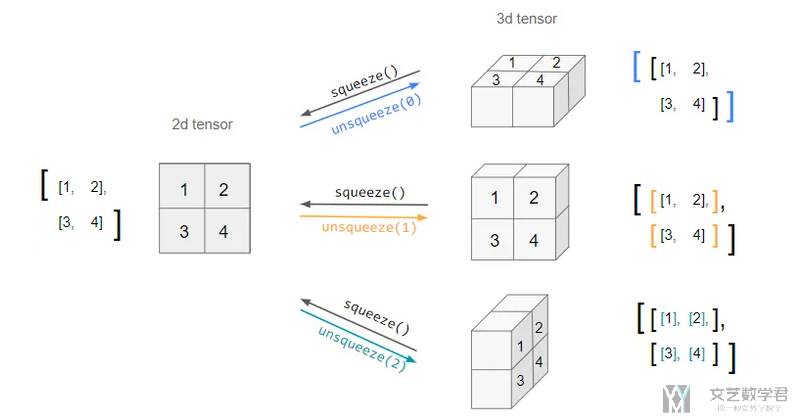
下面看一个具体的例子。我们创建一个 tensor,大小为 2×2:
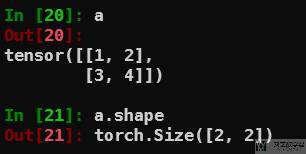
接着使用 unsqueeze 将其大小变为 2×1×2:
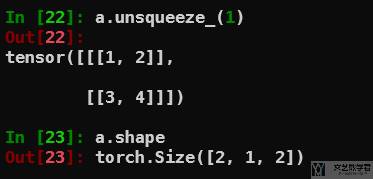
最后可以使用 squeeze 删除指定维度,此时从 2×1×2 变为 2×2:
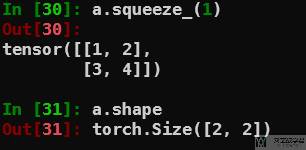
参考资料,torch.squeeze and torch.unsqueeze – usage and code examples
使用 expand 重复 tensor
例如我们现在有一个 2×3 的向量,如下所示:
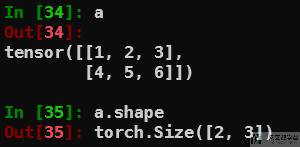
我们希望将其重复 3 次,变为 3×2×3,可以使用 expand,如下所示:
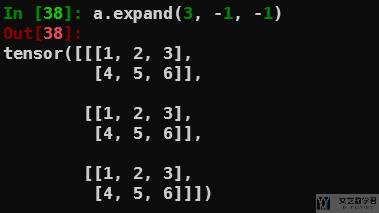
使用 transpose 交换 axis(swap the axis)
例如现在有一个图像数据,我们将 channel 和 batchsize 弄反了,为 channel×batchsize×K,我们想要转换为 batchsize×channel×K。下面是示例的数据,为 3×2×3 的大小:
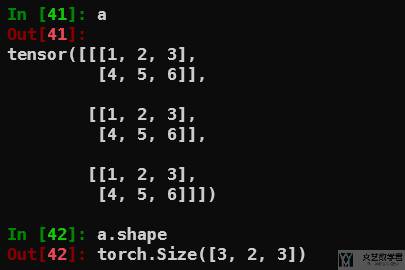
我们希望变为 2×3×3 的大小,使用 transpose 交换 axis=0 和 axis=1:
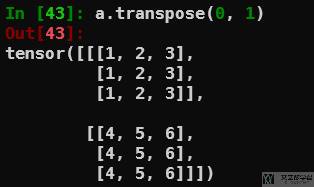
参考资料:TORCH.TRANSPOSE
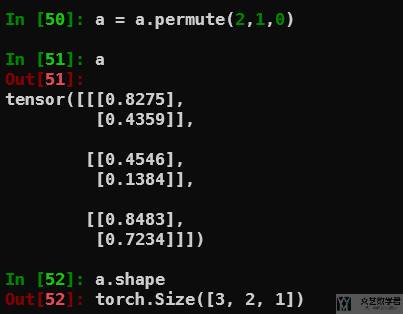
使用 permute 交换任意多个 axis(swap the axis)
上面使用 transpose 交换两个 axis。如果想要交换多个 axis,可以使用 permute 来进行交换。例如现在有一个向量大小为 1×2×3:
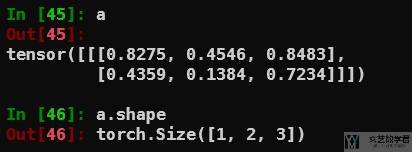
接着使用 permute(2,1,0),交换后的大小为 3×2×1:
广播机制
前面我们都是假设参与运算的两个张量形状相同。在有些情况下,即使两个张量形状不同,也可以通过广播机制 (broadcasting mechanism) 对其中一个或者同时对两个张量的元素进行复制,使得它们形状相同,然后再执行按元素计算。
例如,我们生成两个形状不同的张量,他们的形状分别是 (3, 1) 和 (1, 2):
- x = torch.arange(1, 4).view(3, 1)
- print(x)
- """
- tensor([[1],
- [2],
- [3]])
- """
- y = torch.arange(4, 6).view(1, 2)
- print(y)
- """
- tensor([[4, 5]])
- """
如果要进行按元素运算,必须将它们都扩展为形状 (3, 2) 的张量。具体地,就是将 x 的第 1 列复制到第 2 列,将 y 的第 1 行复制到第 2、3 行。实际上,我们可以直接进行运算,Pytorch 会自动执行广播:
- print(x + y)
- """
- tensor([[5, 6],
- [6, 7],
- [7, 8]])
- """
GPU 还是 CPU
在实际计算中, 我们需要指定使用CPU还是GPU, 首先我们需要检查GPU是否可用.
- torch.cuda.is_available()
我们需要指定tensor是使用GPU还是CPU. 我通常会写成下面这个样子. 这里使用to是首先创建张量, 接着将张量移动到GPU上面.
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- x = torch.tensor([1,2,3]).to(device)
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论