文章目录(Table of Contents)
简介
在Pytorch中(在torchvision.model之中), 会有一些经典的网络结构, 这些网络结构是已经经过训练, 有较好的初始化系数, 我们可以利用这些模型来做进一步的训练.
这一篇我们会介绍如何使用Pytorch中的已经定义好的模型. 我们会使用一个简单的迁移学习来作为例子进行说明.
关于这一篇的相关代码, 可以在github上查看: Pytorch中经典网络结构与迁移学习.ipynb
简单的迁移学习例子
在这里我们会完成一个对蚂蚁和蜜蜂的二分类器. 但是数据集都不大, 我们会使用Pytorch中预训练好的resnet18网络, 来对数据完成训练.
实验的数据集
数据集的结构如下所示, 之后可以使用ImageFolder来封装(实验的数据集就不上传了, 这里就作为一个简单的例子, 说明Pytorch如何使用预训练的网络):
- train(训练集)
- ants
- bees
- val(测试集)
- ants
- bees
我们简单查看一下数据集, 从中选出4张图片来进行展示.
- # 显示一下具体的图像
- dirPath = '/content/drive/My Drive/Machine Learning/dataset/hymenoptera_data_Unzipped/'
- imageList = [dirPath+'hymenoptera_data/train/ants/178538489_bec7649292.jpg', dirPath+'hymenoptera_data/train/ants/424873399_47658a91fb.jpg',
- dirPath+'hymenoptera_data/train/ants/533848102_70a85ad6dd.jpg', dirPath+'hymenoptera_data/train/bees/196658222_3fffd79c67.jpg']
- fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(6,6))
- for i, img_path in enumerate(imageList):
- img_check1 = cv2.imread(img_path, cv2.IMREAD_COLOR)
- img_check1 = cv2.cvtColor(img_check1, cv2.COLOR_BGR2RGB) # BGR => RGB
- # 图片进行显示
- axes[i//2, i%2].axis("off")
- axes[i//2, i%2].imshow(img_check1)
- fig.tight_layout()

数据预处理
在数据预处理的时候, 我们会对原始图片进行旋转等操作, 这样增加数据的多样性(这里并没有增加数据的数量, 只是增加了多样性)
- mean = np.array([0.5, 0.5, 0.5])
- std = np.array([0.25, 0.25, 0.25])
- data_transforms = {
- 'train': transforms.Compose([
- # 加入旋转等数据增强技术,加大模型训练的难度,提高模型的稳健性
- transforms.RandomResizedCrop(224), # 随机剪裁
- transforms.RandomHorizontalFlip(), # 随机水平翻转
- transforms.ToTensor(),
- transforms.Normalize(mean, std)
- ]),
- # 测试集输入时,无需加入旋转等操作
- 'val': transforms.Compose([
- # resize 操作的目的是将任意大小的图片转为模型规定的输入大小
- transforms.RandomResizedCrop(224),
- transforms.ToTensor(),
- transforms.Normalize(mean, std)
- ]),
- }
数据的封装
上面定义好数据预处理的内容之后, 下面对数据进行封装. 首先从image放入dataset, 再将dataset传入dataloader中去.
- dirPath = '/content/drive/My Drive/Machine Learning/dataset/hymenoptera_data_Unzipped/hymenoptera_data'
- # 将数据集封装到 PyTorch 中数据加载器中
- image_datasets = {x: torchvision.datasets.ImageFolder(os.path.join(dirPath, x), data_transforms[x]) for x in ['train', 'val']}
- dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=20, shuffle=True, num_workers=0) for x in ['train', 'val']}
接着我们看一下训练集和测试集里面ants和bees两种类别图片各自的数量.
- dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
- # 看一下训练集和测试集里面两类的数量
- print('Train: ', image_datasets['train'].targets.count(0), image_datasets['train'].targets.count(1))
- print('Test:', image_datasets['val'].targets.count(0), image_datasets['val'].targets.count(1))
- """
- Train: 123 121
- Test: 70 83
- """
模型的建立
因为这里我们会使用预先训练好的模型, 使用预先初始化好的系数. 我们使用resnet18网络.
- model = torchvision.models.resnet18(pretrained=True).to(device)
但是, 因为在原始的resnet18中, output是1000. 但是在我们的这个需求里面, output是2. 所以我们修改他的output.
- num_ftrs = model.fc.in_features
- model.fc = nn.Linear(num_ftrs, 2) # 重新定义 fc:输入节点数不变的情况下,将输出节点改为 2
- model = model.to(device)
- model.fc
- """
- Linear(in_features=512, out_features=2, bias=True)
- """
定义损失函数与优化器
接着我们定义了损失函数和优化器. 同时我们定义了一个可以让学习率逐渐下降的lr_scheduler.
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
- step_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
模型的训练与测试
最后, 我们对上面的模型开始训练, 并进行测试. 同时这次, 我们会保存模型在测试集上最优的一次结果, 保存此时模型的系数. 模型的系数保存在best_model_wts中.
- best_model_wts = copycopy.deepcopy(model.state_dict())
- best_acc = 0.0
- num_epochs = 10
- n_total_steps = len(dataloaders['train'])
- LossList = [] # 记录每一个epoch的loss
- AccuryList = [] # 每一个epoch的accury
- for epoch in range(num_epochs):
- # -------
- # 开始训练
- # -------
- model.train() # 切换为训练模型
- totalLoss = 0
- for i, (images, labels) in enumerate(dataloaders['train']):
- images = images.to(device) # 图片大小转换
- labels = labels.to(device)
- # 正向传播以及损失的求取
- outputs = model(images)
- loss = criterion(outputs, labels)
- totalLoss = totalLoss + loss.item()
- # 反向传播
- optimizer.zero_grad() # 梯度清空
- loss.backward() # 反向传播
- optimizer.step() # 权重更新
- step_lr_scheduler.step()
- if (i+1) % 3 == 0:
- print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}, LR: {:.4f}'.format(epoch+1, num_epochs, i+1, n_total_steps, totalLoss/(i+1), optimizer.param_groups[0]['lr']))
- LossList.append(totalLoss/(i+1))
- # ---------
- # 开始测试
- # ---------
- model.eval()
- with torch.no_grad():
- correct = 0
- total = 0
- for images, labels in dataloaders['val']:
- images = images.to(device)
- labels = labels.to(device)
- outputs = model(images)
- _, predicted = torch.max(outputs.data, 1) # 预测的结果
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- acc = 100.0 * correct / total # 在测试集上总的准确率
- AccuryList.append(acc)
- if acc > best_acc:
- best_acc = acc
- best_model_wts = copycopy.deepcopy(model.state_dict())
- print('更新模型参数, {}'.format(epoch))
- print('Accuracy of the network on the {} test images: {} %'.format(total, acc))
- print("模型训练完成")
- """
- Epoch [10/10], Step [3/13], Loss: 0.1648, LR: 0.0001
- Epoch [10/10], Step [6/13], Loss: 0.1952, LR: 0.0001
- Epoch [10/10], Step [9/13], Loss: 0.2066, LR: 0.0001
- Epoch [10/10], Step [12/13], Loss: 0.2060, LR: 0.0001
- Accuracy of the network on the 153 test images: 93.4640522875817 %
- 模型训练完成
- """
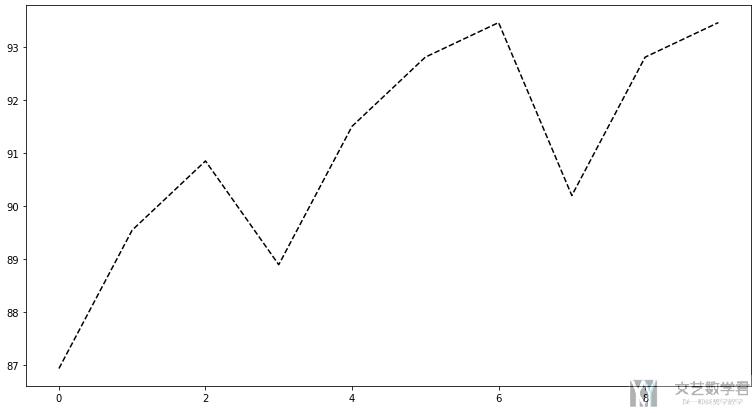
最终我们的模型在测试集上的准确率可以得到90%以上. 准确率如下图所示:
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论