文章目录(Table of Contents)
简介
在上一篇中, 我们介绍了关于正向传播与反向传播的例子. 但是其中我们只能求叶子节点的梯度. 也就是在下图中, Pytorch只会保存d和e的梯度, 张量b和c的梯度在计算完毕之后会释放.
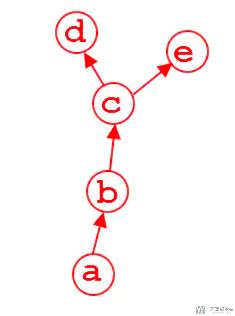
但是在调试过程中, 有时候我们需要对中间变量梯度进行监控, 以确保网络的有效性, 这个时候我们需要打印出非叶节点的梯度, 为了实现这个目的, 我们可以通过两种手段进行, 分别是:
- retain_grad()
- hook
参考资料
- 示例代码: 正向传播,反向传播与非叶子节点梯度保存
- 这一篇还是写得很好的: pytorch获取中间变量的梯度
- 这一篇是我之前写得, 但是没有单独拿出来写: hook的使用
retain_grad()
retain_grad()显式地保存非叶节点的梯度, 当然代价就是会增加显存的消耗(对比hook函数的方法则是在反向计算时直接打印, 因此不会增加显存消耗.)
但是使用起来retain_grad()要比hook函数方便一些, 我们还是使用之前的例子, 有如下的计算图.
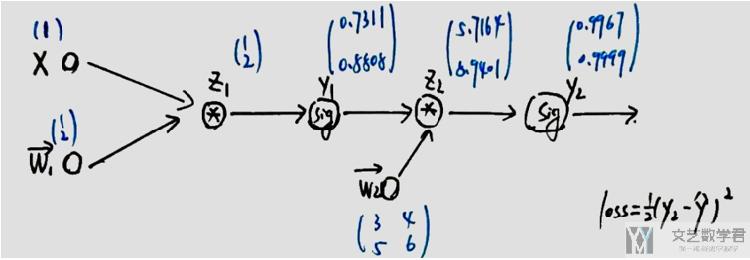
正常情况下, 我们在反向传播之后, 只有w1和w2的导数, 但是我们可以在z1等变量后面加上retain_grad, 使其梯度保持, 如下所示:
- def forwrad(x, y, w1, w2):
- # 其中 x,y 为输入数据,w为该函数所需要的参数
- z_1 = torch.mm(w1, x)
- z_1.retain_grad()
- y_1 = torch.sigmoid(z_1)
- y_1.retain_grad()
- z_2 = torch.mm(w2, y_1)
- z_2.retain_grad()
- y_2 = torch.sigmoid(z_2)
- y_2.retain_grad()
- loss = 1/2*(((y_2 - y)**2).sum())
- loss.retain_grad()
- return loss, z_1, y_1, z_2, y_2
接着我们进行正向传播和反向传播.
- # 测试代码
- x = torch.tensor([[1.0]])
- y = torch.tensor([[1.0], [0.0]])
- w1 = torch.tensor([[1.0], [2.0]], requires_grad=True)
- w2 = torch.tensor([[3.0, 4.0], [5.0, 6.0]], requires_grad=True)
- # w2 = torch.tensor([[3.0, 1.0], [1.0, 6.0]], requires_grad=True)
- # 正向
- loss, z_1, y_1, z_2, y_2 = forwrad(x, y, w1, w2)
- # 反向
- loss.backward() # 反向传播,计算梯度
接下来就可以查看中间变量的梯度了. 我们在下面举几个例子, 完整的可以在Github仓库中进行查看, 正向传播,反向传播与非叶子节点梯度保存. (下面图片可以在新窗口打开查看大图)

hook的使用
使用retain_grad会消耗额外的显存, 我们可以使用hook在反向计算的时候进行保存. 还是上面的例子, 我们使用hook来完成.
- # 我们可以定义一个hook来保存中间的变量
- grads = {} # 存储节点名称与节点的grad
- def save_grad(name):
- def hook(grad):
- grads[name] = grad
- return hook
对于forward函数, 我们不需要进行修改, 保持最基本的样子即可.
- def forwrad(x, y, w1, w2):
- # 其中 x,y 为输入数据,w为该函数所需要的参数
- z_1 = torch.mm(w1, x)
- y_1 = torch.sigmoid(z_1)
- z_2 = torch.mm(w2, y_1)
- y_2 = torch.sigmoid(z_2)
- loss = 1/2*(((y_2 - y)**2).sum())
- return loss, z_1, y_1, z_2, y_2
接着进行正向传播和反向传播, register_hook是发生在backward之前的动作.
- # 测试代码
- x = torch.tensor([[1.0]])
- y = torch.tensor([[1.0], [0.0]])
- w1 = torch.tensor([[1.0], [2.0]], requires_grad=True)
- w2 = torch.tensor([[3.0, 4.0], [5.0, 6.0]], requires_grad=True)
- # 正向传播
- loss, z_1, y_1, z_2, y_2 = forwrad(x, y, w1, w2)
- # hook中间节点
- z_1.register_hook(save_grad('z_1'))
- y_1.register_hook(save_grad('y_1'))
- z_2.register_hook(save_grad('z_2'))
- y_2.register_hook(save_grad('y_2'))
- loss.register_hook(save_grad('loss'))
- # 反向传播
- loss.backward()
最后我们可以打印出中间变量的梯度.
- print(grads['z_1'])
- print(grads['y_1'])
- print(grads['z_2'])
- print(grads['y_2'])
- print(grads['loss'])
- """
- tensor([[1.2243e-04],
- [7.8005e-05]])
- tensor([[0.0006],
- [0.0007]])
- tensor([[-1.0728e-05],
- [ 1.3098e-04]])
- tensor([[-0.0033],
- [ 0.9999]])
- tensor(1.)
- """
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论