文章目录(Table of Contents)
前言
这一篇文章,会简单介绍一下CNN在NLP(自然语言处理)上的应用,因为我也是初看,就根据两篇论文做一下简单的介绍。
Convolutional Neural Networks for Sentence Classification
Ref. Kim Y . Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.
下面简单讲一下这一篇文章的计算步骤,可以结合下面这张图来看:
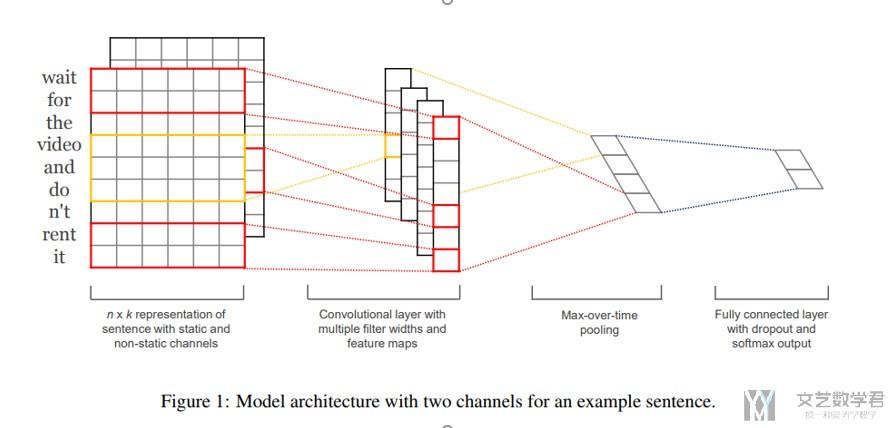
- Let x_i ∈ R be the k-dimensional word vector corresponding to the i-th word in the sentence. (x_i表示句子中第i个单词, 一个单词用k维表示)
- A sentence of length n is represented as, x_1:_n = x1 ⊕ x2 ⊕ . . . ⊕ xn , where ⊕ is the concatenation operator.(于是n个单词的句子这么表示,见上图最左侧)
- A convolution operation involves a filter w ∈ R_hk, which is applied to a window of h words to produce a new feature. For example, a feature c_i is generated from a window of words x_i:_i+h−1 by c_i = f(w · x_i:_i+h−1 + b).
- This filter is applied to each possible window of words in the sentence {x_1:_h, x_2:_h+1, . . . , x_n−h+1:_n} to produce a feature map, c = [c1, c2, . . . , cn−h+1]. (一个filter会生成这样一组C)
- We then apply a max-overtime pooling operation over the feature map and take the maximum value c’ = max{c} as the feature corresponding to this particular filter. (Pooling层就取上面C的最大值, 一个filter经过Pooling之后, 只会有一个值)
接下来,这一篇文章测试了不同的参数(Hyperparameters and Training)
- Rectified linear units(ReLU)
- Filter windows (h) of 3, 4, 5 with 100 feature maps each
- Dropout rate (p) of 0.5
- l2 constraint (s) of 3
- Mini-batch size of 50.
也测试了使用不同的word vector的效果
- We use the publicly available word2vec vectors that were trained on 100 billion words from Google News.
- The vectors have dimensionality of 300 and were trained using the continuous bag-of-words architecture.
他测试的几个模型如下所示:
- CNN-rand : Our baseline model where all words are randomly initialized and then modified during training. (随机初始化, 有embed层)
- CNN-static : A model with pre-trained vectors from word2vec. All words— including the unknown ones that are randomly initialized—are kept static and only the other parameters of the model are learned. (使用Pre-trained的vector初始化, 没有embedding层)
- CNN-non-static : Same as above but the pretrained vectors are fine-tuned for each task. (使用Pre-trained的vector初始化, 有embedding层)
- CNN-multichannel : A model with two sets of word vectors. Each set of vectors is treated as a ‘channel’ and each filter is applied to both channels, but gradients are backpropagated only through one of the channels. Hence the model is able to fine-tune one set of vectors while keeping the other static. Both channels are initialized with word2vec. (使用Pre-trained的vector初始化, 一个word有两个vector, 一个有embedding层, 一个没有embedding, 相当于图片中的双通道)
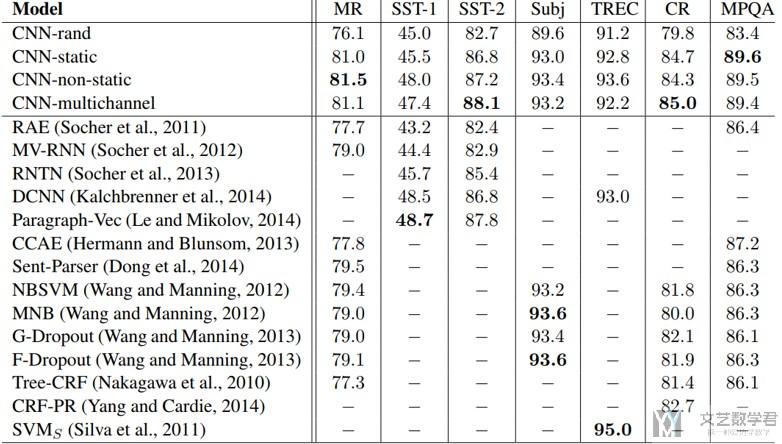
文章的测试结果(上面四个model的测试结果)如下所示:
A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification
Ref. Zhang Y, Wallace B. A sensitivity analysis of (and practitioners' guide to) convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1510.03820, 2015.
这篇文章其实主要是在研究不同大小的卷积核,不同数量的feature maps for each filter,不同的池化方法,不同的激活函数,不同的正则化方法,对CNN应用在NLP上的影响。
下面就按文章的顺序进行介绍,主要介绍一些我觉得比较重要的吧。
Abstract
However, these models require practitioners to specify an exact model architecture and set accompanying hyperparameters, including the filter region size, regularization parameters, and so on.
It is currently unknown how sensitive model performance is to changes in these configurations for the task of sentence classification.(模型对参数的敏感性)
We thus conduct a sensitivity analysis of one-layer CNNs to explore the effect of architecture components on model performance; our aim is to distinguish between important and comparatively inconsequential design decisions for sentence classification. (这篇文章主要来探寻网络的结构,看一下哪些设置是重要的,哪些是不重要的)
When assessing the performance of a model (or a particular configuration thereof), it is imperative to consider variance. Therefore, replications of the cross-fold validation procedure should be performed and variances and ranges should be considered. (以往的文章只考虑了mean, 这里考虑了variances, 因为模型的复杂性, 需要查看模型的稳定性)
Configuration
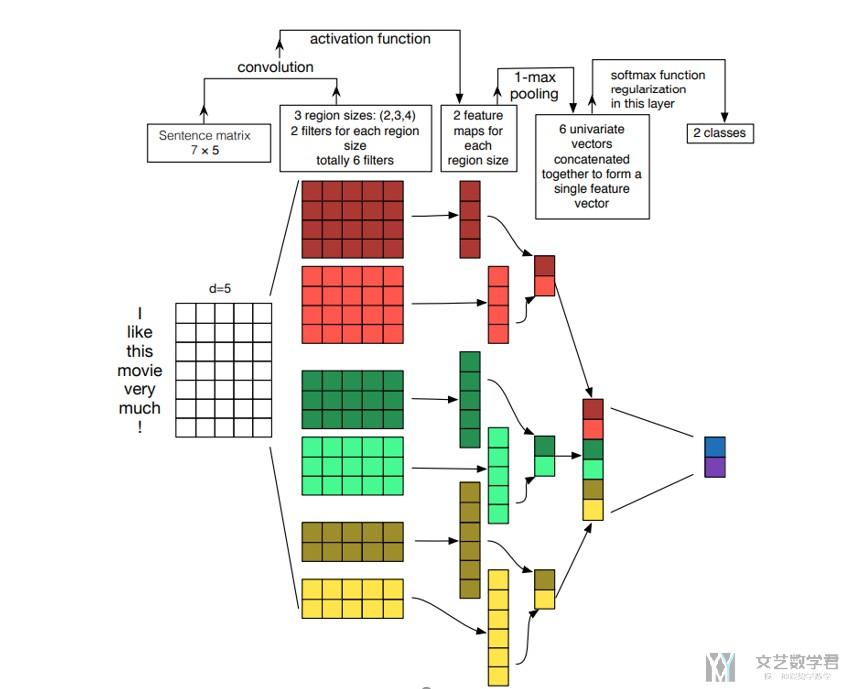
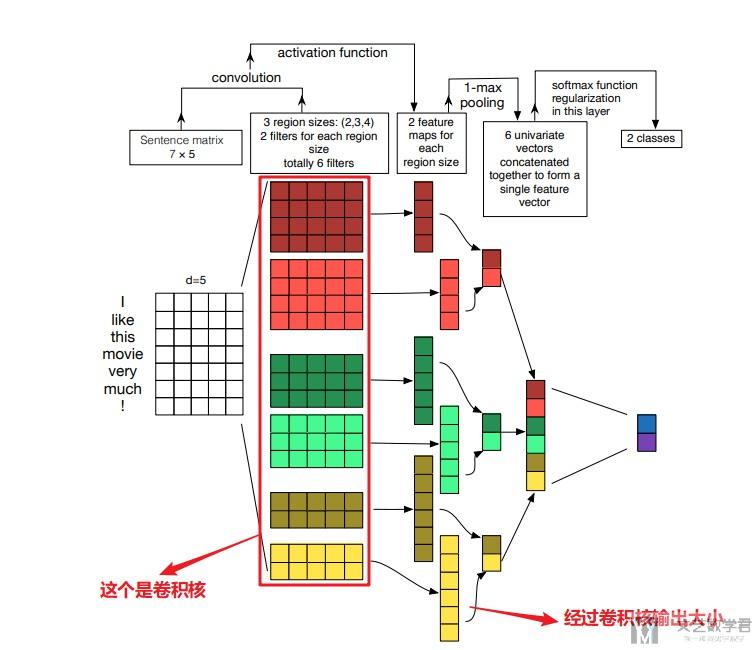
关于上面的这张图片,下面简单介绍一下。
下面是作者所测试的几个指标,和作者最后给出的结论。
- Input word vectors : Different representations perform better for different tasks.
- Filter region size : The filter region size can have a large effect on performance, and should be tuned.
- Numbers of feature maps for each filter region size : The number of feature maps can also play an important role in the performance, and increasing the number of feature maps will increase the training time of the model.
- Pooling strategy : 1-max pooling uniformly outperforms other pooling strategies.
- Activation function : Consider different activation functions if possible: ReLU and tanh are the best overall candidates. And it might also be worth trying no activation function at all for our one-layer CNN.
- Regularization : Regularization has relatively little effect on the performance of the model.
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论