文章目录(Table of Contents)
简介
这一篇是关于模型可解释性,文章会介绍关于SHAP Value的方法。同时介绍一下如何简单的绘制结果。还是把参考资料放在最前面。
在看这个之前, 建议先查看LIME和Shapley Value的相关的内容. 链接分别如下:
我也是用SHAP的思想, 做了用于入侵检测系统的结果的解释问题, 链接如下: An Explainable Machine Learning Framework for Intrusion Detection Systems
参考资料
- 一本很全的资料(这是一份很好的资料) : Interpretable Machine Learning
- 整体了解SHAP(整体结构参考了这篇文章) : Interpreting your deep learning model by SHAP
- 也是一个很好的资料(对SHAP那篇文章做了解释, 值得一看): One Feature Attribution Method to (Supposedly) Rule Them All: Shapley Values
- 关于NLP模型的解释 : 3 ways to interpretate your NLP model to management and customer
- SHAP的帮助文档 : SHAP (SHapley Additive exPlanations)
SHAP Value方法的介绍
SHAP的目标就是通过计算x中每一个特征对prediction的贡献, 来对模型判断结果的解释. SHAP方法的整个框架图如下所示:
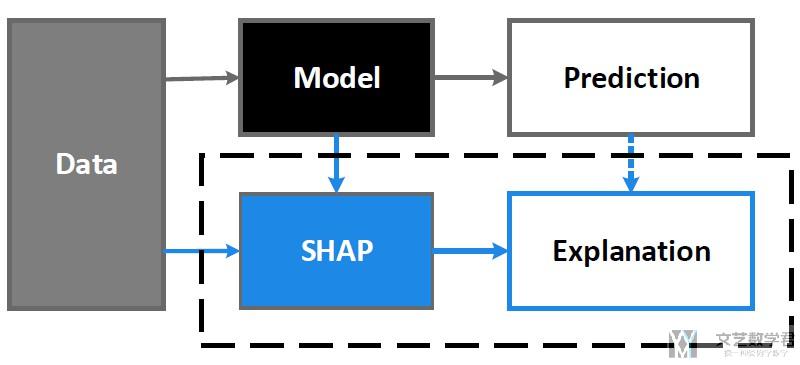
SHAP Value的创新点是将Shapley Value和LIME两种方法的观点结合起来了. One innovation that SHAP brings to the table is that the Shapley value explanation is represented as an additive feature attribution method, a linear model. That view connects LIME and Shapley Values.
SHAP解释的时候使用下面的表达式, 这个和LIME中的原理是相似的(最大的不同是SHAP中设置了不同的distance的定义, 我们后面会讲):
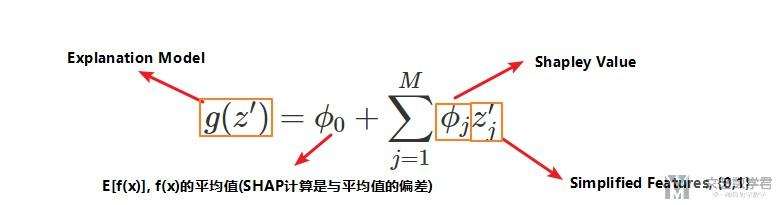
上面的Simplified Features取值只能是{0, 1}, 当其取值为1的时候, 表示的是这个特征是present(也就是这个特征的取值与我们要解释的instance x中对应的特征是相同的), 当其特征是0的时候, 表示这个特征是absent(这时候我们从数据集中取一个这个特征的值, 其他数据在这个特征上的取值).
对于我们要解释的instance x来说, 也就是所有的Simplified Features都是1. 此时上面的式子可以化简为:
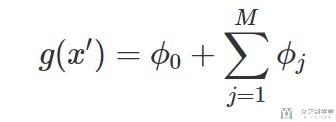
这个时候, 就可以看成每一个特征的Shapley Value的和做出的贡献, 使得预测结果从均值变为我们预测的结果, 也就是g(x').
在原始论文中, 作者提出了KernelSHAP和TreeSHAP. 下面我们只详细介绍KernelSHAP.
KernelSHAP的简单介绍
KernelSHAP包含下面的5个步骤:
- 初始化一些数据, z', 作为Simplified Features, 例如随机生成(0, 1, 0, 1), (1, 1, 1, 0)等.
- 将上面的Simplified Features转换到原始数据空间, 并计算对应的预测值, f(h(z')).
- 对每一个z'计算对应的权重(这里权重的计算是关键, 也是SHAP与LIME不同的地方)
- 拟合线性模型
- 计算出每一个特征的Shapley Value, 也就是线性模型的系数.
对于上面的第二个步骤, 我们做一下解释, 当Simplified Features是1的时候, 使用原始数据的特征, 当Simplified Features是0的时候, 我们使用其他的数据进行替换(这种置换的方式会存在一些问题, 当特征之间不是独立的, 而是相互有关联的, 那么这样生成的数据可能是实际上不存在的), 如下图所示.
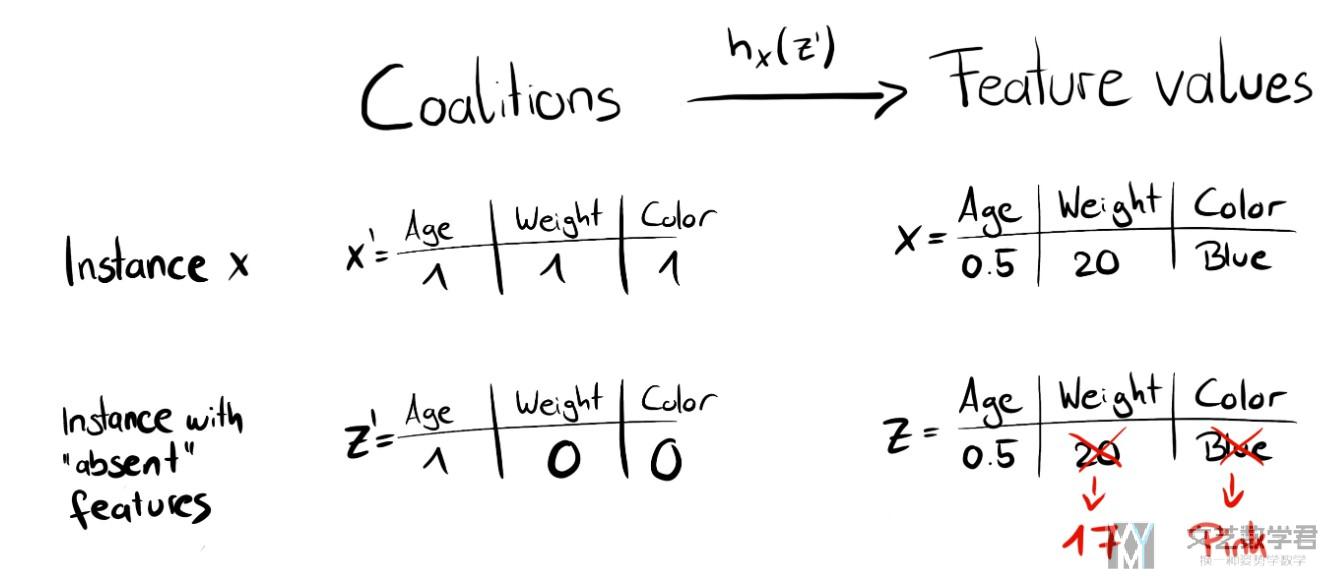
下面就是重点介绍对z'权重的计算了, 这个也是SHAP最大的不同. (The big difference to LIME is the weighting of the instances in the regression model.)
LIME根据相似度进行计算距离, 如sample的数据中有很多0, 也就是会和原始数据有很大的不同, 那么他的距离是远的, 也就是他的权重会是小的. (LIME weights the instances according to how close they are to the original instance. The more 0's in the coalition vector, the smaller the weight in LIME.)
SHAP中距离的计算根据Simplified Features中0的数量, 若有很多0或是很多1, 他的权重都是比较高的.
- 这是因为若都是0, 只有一个是1, 那么我们可以很好的计算出那个是1的特征的贡献.
- 若只有一个是0, 我们可以计算出那个是0的特征的贡献.
- 如果一半是0, 一半是1, 那么会有很多种组合, 就很难计算出每一个特征的贡献(下面是原文).
SHAP weights the sampled instances according to the weight the coalition would get in the Shapley value estimation. Small coalitions (few 1's) and large coalitions (i.e. many 1's) get the largest weights. The intuition behind it is: We learn most about individual features if we can study their effects in isolation.
- If a coalition consists of a single feature, we can learn about the features' isolated main effect on the prediction.
- If a coalition consists of all but one feature, we can learn about this features' total effect (main effect plus feature interactions).
- If a coalition consists of half the features, we learn little about an individual features contribution, as there are many possible coalitions with half of the features.
所以最终的SHAP kernel中的weight的计算公式如下:

使用这个weight和线性回归, 计算出的结果就是Shapley Value. (If you would use the SHAP kernel with LIME on the coalition data, LIME would also estimate Shapley values!)
到这里为止, 我们就有了data, target和weight来计算我们需要的线性回归的式子(也就是下面的式子).
我们可以通过减少下面function的loss的方法, 来得到上面的回归方程的系数(也就是Shapley Value). (The estimated coefficients of the model are the Shapley values.)
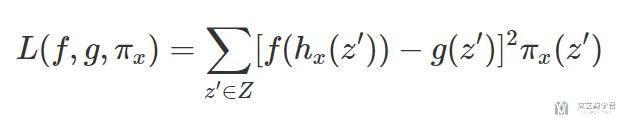
SHAP的简单使用方法
说完上面的SHAP的方法介绍之后, 我们看一下在具体使用场景中, 我们需要如何来进行实现,. 我们可以直接使用python中的SHAP的库来进行实现.
项目地址(这里面会有最详细的介绍, 下面只是简单介绍一下我使用到的功能): SHAP
SHAP provides multiple explainers for different kind of models.
- TreeExplainer : Support XGBoost, LightGBM, CatBoost and scikit-learn models by Tree SHAP.
- DeepExplainer (DEEP SHAP) : Support TensorFlow and Keras models by using DeepLIFT and Shapley values.
- GradientExplainer : Support TensorFlow and Keras models.
- KernelExplainer (Kernel SHAP) : Applying to any models by using LIME and Shapley values.
一些函数具体的使用方式, 可以查看SHAP的帮助文档, 文档的地址如下:
SHAP的帮助文档 : SHAP (SHapley Additive exPlanations)
下面我们来看一下具体的使用例子, 来看一下使用SHAP如何来进行模型的解释.
需要注意--出现报错的解决
在使用Pytorch进行模型的创建和解释的时候, 我们需要对模型创建的时候进行注意, 需要使用Sequential的方式进行创建. 否则在解释的时候会出现问题. 参考资料: PyTorch Deep Explainer
我们创建模型的时候应该使用下面的方式进行创建, 即使用Sequential的方式进行创建.
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv_layers = nn.Sequential(
- nn.Conv2d(1, 10, kernel_size=5),
- nn.MaxPool2d(2),
- nn.ReLU(),
- nn.Conv2d(10, 20, kernel_size=5),
- nn.Dropout(),
- nn.MaxPool2d(2),
- nn.ReLU(),
- )
- self.fc_layers = nn.Sequential(
- nn.Linear(320, 50),
- nn.ReLU(),
- nn.Dropout(),
- nn.Linear(50, 10),
- nn.Softmax(dim=1)
- )
- def forward(self, x):
- x = self.conv_layers(x)
- x = x.view(-1, 320) # doesn't affect the gradient, so can be outside an nn.Module object
- x = self.fc_layers(x)
- return x
而不要使用下面的方式进行创建.
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
- self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
- self.conv2_drop = nn.Dropout2d()
- self.fc1 = nn.Linear(320, 50)
- self.fc2 = nn.Linear(50, 10)
- def forward(self, x):
- x = F.relu(F.max_pool2d(self.conv1(x), 2))
- x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
- x = x.view(-1, 320)
- x = F.relu(self.fc1(x))
- x = F.dropout(x, training=self.training)
- x = self.fc2(x)
- return F.softmax(x, dim=1)
SHAP例子分析--Iris dataset
这一部分我们使用KernelExplainer来进行模型的解释, 使用KernelExplainer是不能直接传入训练好的模型的, 也是需要和LIME一样, 写成函数的样子.
关于具体内容可以查看LIME部分: Pytorch例子演示及LIME使用例子
下面部分的完整代码可以在Github中找到: Github-SHAP笔记
准备工作
我们需要导入需要使用的库.
- import shap
- shap.initjs() # 用来显示的
创建解释器
- # 新建一个解释器
- # 这里传入两个变量, 1. 模型; 2. 训练数据
- explainer = shap.KernelExplainer(batch_predict, x)
- print(explainer.expected_value) # 输出是三个类别概率的平均值
- """
- [0.32909563 0.33329453 0.33760984]
- """
这里最后打印出的是每一类样本的平均预测的值, 三类, 每一类的值还是很平均的.
对单个数据进行解释
接下来我们对单个数据进行解释, 与LIME那一部分一样, 我们对数据集中第5个数据进行解释.
- # 选择一个数据进行解释(还是选择第5个数据)
- shap_values = explainer.shap_values(x[5])
解释结果可视化
接着我们将上面解释的结果进行可视化.
- # 对单个数据进行解释
- shap.force_plot(base_value=explainer.expected_value[1],
- shap_values=shap_values[1],
- feature_names=['sepal length','sepal width','petal length','petal width'],
- features=x[5])

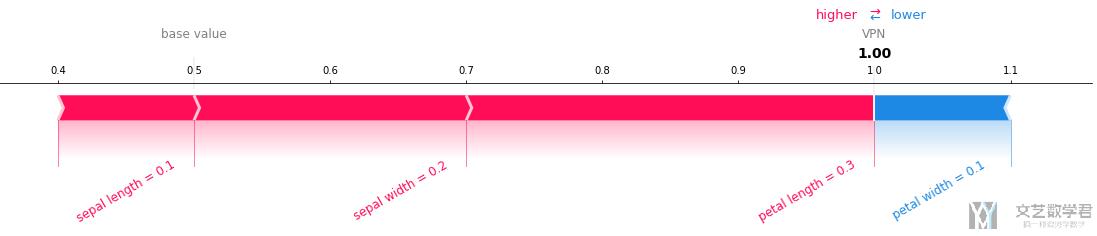
上面绘图的方式也可以单独拿出来进行绘制,下面是一个简单的例子:
- shap.force_plot(base_value=0.5,
- shap_values=np.array([0.1, 0.2, 0.3, -0.1]),
- feature_names=['sepal length','sepal width','petal length','petal width'],
- features=np.array([0.1, 0.2, 0.3, 0.1]),
- out_names='VPN',
- text_rotation=30,
- matplotlib=True)
最终的结果如下图所示,这里负数就是蓝色,正数就是红色:
对特征重要度进行解释
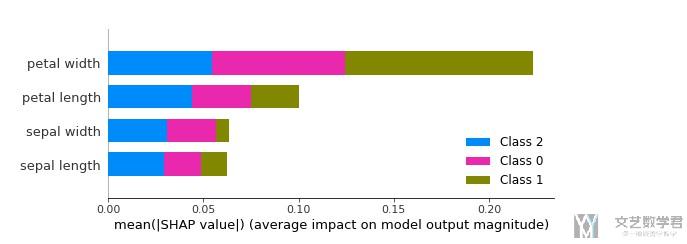
除了上面对于单个数据进行解释之外, 我们还可以对整个模型的特征的重要度进行分析.
- # 对特征重要度进行解释
- shap_values = explainer.shap_values(x)
- # --------
- # 进行绘图
- # --------
- shap.summary_plot(shap_values=shap_values,
- features=x,
- feature_names=['sepal length','sepal width','petal length','petal width'],
- plot_type='bar')
SHAP例子分析--每一类分析
下面使用以下DeepExplainer, 使用这个的话是可以直接传入模型的.
对单个数据的解释
首先我们看一下使用SHAP对单个数据来进行解释. 我们首先新建一个解释器, 这里的X_exp是用来计算baseline的, 同时也是为后面解释做准备的.
- # 新建一个解释器
- X_exp = torch.from_numpy(XData).float()
- explainer = shap.DeepExplainer(fullModel.to(device), X_exp.to(device))
- print(explainer.expected_value)
接着我们随机选出一个数据来进行解释.
- # 随机选择1个数据, 来进行解释
- X_exp = XData[-3]
- X_tensor = torch.from_numpy(X_exp).unsqueeze(0).float().to(device)
- # 计算样本的shape value
- shap_values = explainer.shap_values(X_tensor)
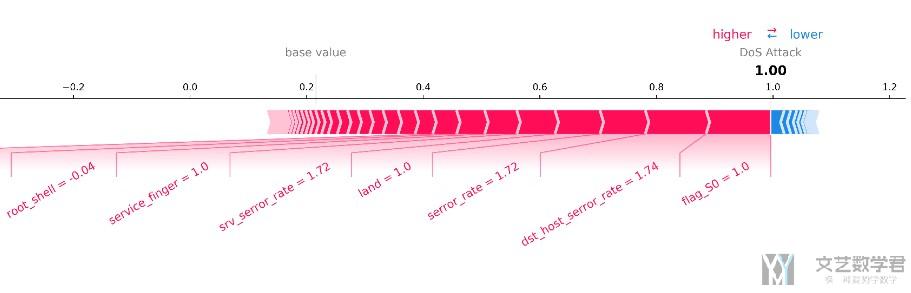
最后我们将结果画出(这里我们使用直接保存为文件的形式, 这样得到的图像的清晰度可以控制), 同时我们在这里的feature控制一下小数点的位数.
- # 得到特征的名字和解释数据的特征的值
- feature_names=list(dfDataTrain.columns[:-4])
- features = features = np.around(X_exp,2) # 解释的数据的特征的值
- # 对单个数据进行解释
- t = shap.force_plot(base_value=explainer.expected_value[YData[-3]],
- shap_values=shap_values[YData[-3]],
- feature_names=feature_names,
- features=features,
- out_names = 'DoS Attack',
- text_rotation=30,
- matplotlib=True,
- show=False)
最终我们将我们的图像进行保存即可.
- t.set_facecolor('white') # 把背景颜色设置为白色
- t.savefig('filename.png', bbox_inches = 'tight', dpi=500) # 保存图片
最终的结果如下图所示, 我们整个数据集对这个label的平均预测值是0.2, 这里对这个样本的预测值是接近1, 同时是flag_S0=1等特征对这个预测结果有很大的作用.
对特征重要度的解释
SHAP可以用来进行模型的整体解释, 我们只需要将训练集中所有数据的每一个特征都计算一遍, 计算平均值即可. 这里我们绘制出对每一个特征重要度的解释.
下面是示例代码, 对于多分类来说, 我们可以绘制出每一类特征的重要度.
- # 随机选择1个数据, 来进行解释
- X_exp = XExplainDate
- X_tensor = torch.from_numpy(X_exp).float().to(device)
- # 计算样本的shape value
- shap_values = explainer.shap_values(X_tensor)
- # ---------
- # 进行绘图
- # ---------
- plt.figure(dpi=500) # 设置图片的清晰度
- fig = plt.gcf() # 获取后面图像的句柄
- shap.summary_plot(shap_values=shap_values,
- features = XData, # 所有样本的feature的值
- feature_names=list(dfDataTrain.columns[:-4]), # 特征的名字
- plot_type = 'bar',
- max_display=20,
- show=False)
为了最终可以将图像进行保存, 我们需要对背景的颜色进行设置.
- fig.set_facecolor('white')
- fig
之后将图像右键另存为即可. 最终的效果是如下图所示(这是同时展示多个分类的结果):
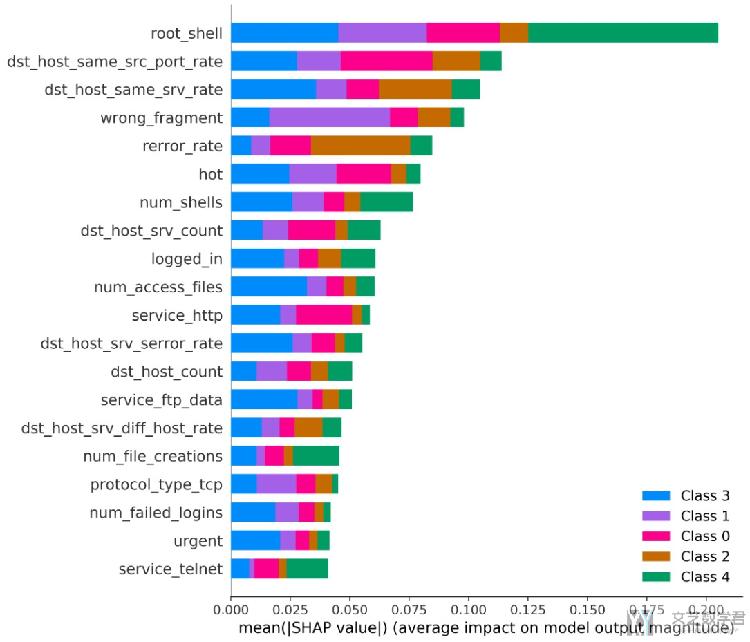
我们也是可以对某一个分类进行解释, 查看在这个分类下的特征的重要度, 这个时候就是在绘制的时候指定shap_values即可.
- shap.summary_plot(shap_values=shap_values[1],
- features = XData, # 所有样本的feature的值
- feature_names=list(dfDataTrain.columns[:-4]), # 特征的名字
- plot_type = 'bar',
- max_display=20,
- show=False)
最终的绘制效果如下图所示:
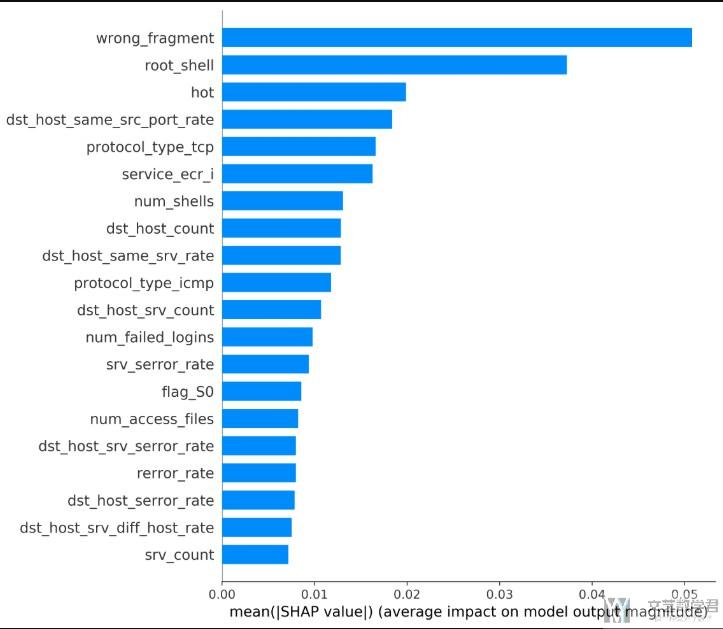
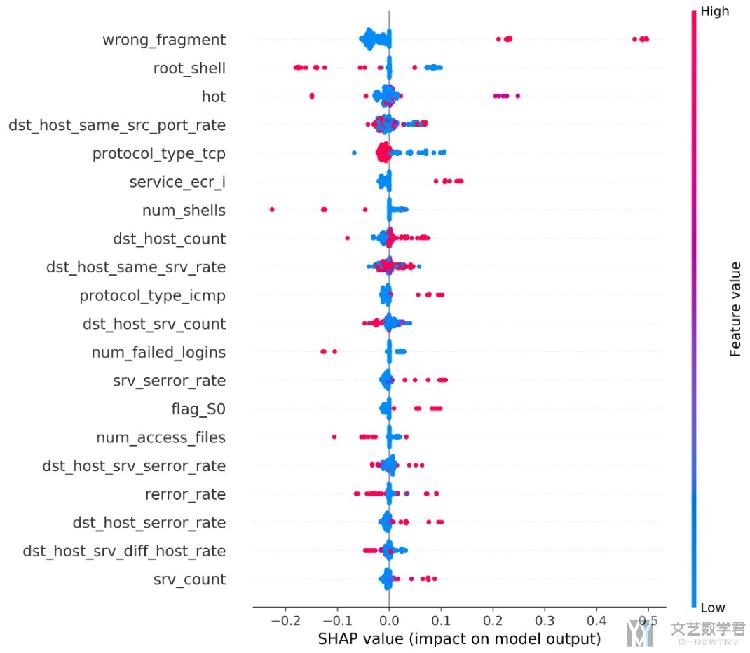
特征取值与重要度之间的关系
我们只需要将上面的plot_type = 'bar'替换为plot_type = 'dot' (需要注意, 这个图只支持二分类, 多分类是不支持的), 就可以绘制出特征的取值与Shapley Value的关系. 如下图所示, x轴表示Shapley Value, 不同的颜色表示特征的大小. 如对于wrong_fragment这个特征来说, 该特征取值较大会对模型判读数据为DoS有一个正向的推动. 这里每一个数据点表示一组数据.
除了上面的绘制方式, 我们还可以绘制出每一个数据点的一个特征的SHAP Value, 我们可以使用下面的方式进行绘制.
- shap.dependence_plot(ind = 'wrong_fragment',
- shap_values=shap_values[1],
- features = XExplainDate, # 所有样本的feature的值
- feature_names=list(dfDataTrain.columns[:-4]), # 特征的名字
- interaction_index = None,
- )
其中ind表示的是我们需要解释的特征, 最终会得到下面的效果图. 图中横坐标表示的该特征的取值, 纵坐标表示的是每一个点对应的SHAP Value.
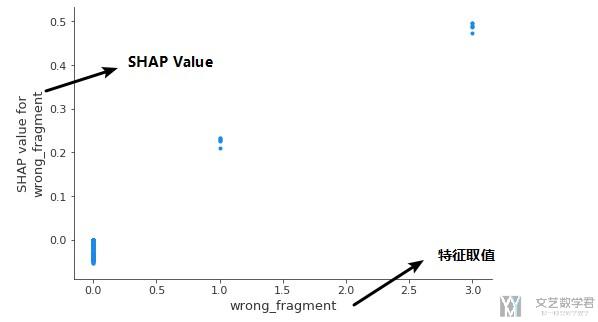
保存图像的方式
我们使用SHAP进行绘图的时候, 可以使用下面的方式进行图片的保存(使用这种方法进行绘图的时候, 可以控制图片的清晰度, 这一部分的内容其实在上面也是已经涉及到了, 在讲对特征进行解释的时候, 但是我们在这里再次强调一遍).
- plt.figure(dpi=1200) # 设置图片的清晰度
- fig = plt.gcf() # 获取后面图像的句柄
- shap.summary_plot(X, show=False)
- fig.set_facecolor('white') # 设置背景为白色
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












2021年8月26日 下午7:56 1F
请问有完整代码吗
2021年9月8日 下午4:18 2F
请问有完整代码吗,可以学习一下吗
2021年9月10日 下午3:54 B1
@ wwy 你好,你可以参考一下这个链接,https://github.com/wmn7/ML_Practice/tree/master/2019_07_08/SHAP