文章目录(Table of Contents)
简介
之前写了两篇强化学习在特定领域内的应用, 包括在入侵检测领域和在信号灯的控制领域.
但是有一些文章是利用强化学习来解决一类通用的问题, 就在这里记录一下这类文章.
Classification with Costly Features Using Deep Reinforcement Learning
- Janisch, Jaromír, Tomáš Pevný, and Viliam Lisý. "Classification with costly features using deep reinforcement learning." In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 3959-3966. 2019.
We study a classification problem where each feature can be acquired for a cost and the goal is to optimize a trade-off between the expected classification error and the feature cost. (这篇文章要解决的问题是, 当获取每一个feature都需要付出cost的时候, 如何使cost最少, 同时准确率也不会下降很多)
We revisit a former approach that has framed the problem as a sequential decision-making problem and solved it by Q-learning with a linear approximation, where individual actions are either requests for feature values or terminate the episode by providing a classification decision. (对于这类问题, 可以使用Q-learning的方法去解决, action是每个feature是否被选入与是否结束, 以目前的features进行判断)
本文的代码链接: Classification with Costly Features using Deep Reinforcement Learning
本文的Post(海报), 这个海报是总结的非常好的, Classification with Costly Features using Deep Reinforcement Learning
目前存在的问题
在实际的分类问题中, 由于有限的资源(time, money and many other), 我们在解决问题的时候需要考虑获取特征需要的花费, 例如:
Medical practitioners strive to make a diagnosis for their patients with high accuracy. Yet at the same time, they want to minimize the amount of money spent on examinations, or the amount of time that all the procedures take. (医生给病人诊断的时候, 希望通过尽可能少的检测来获得较高的准确率) 下图是在医疗领域, 不同检测需要的花费.

In the domain of computer security, network traffic is often analyzed by a human operator who queries different expensive data sources or cloud services and eventually decides whether the currently examined traffic is malicious or benign. (在网络安全领域, 需要人工查询不同的数据来判断流量是恶意的还是正常的, 我们希望通过尽可能少的查询获得较高的准确率)
对于上面这里, 希望在features cost和accuracy上获得平衡的问题, 我们称为Classification with Costly Features (CwCF). The goal is to minimize the expected classification error, while also minimizing the expected incurred cost.
上面的问题, 我们可以理解为是Sequential Decision-Making Problem. 具体的过程如下所示, 依次获得特征, 值得获得足够的信息可以用来进行分类.
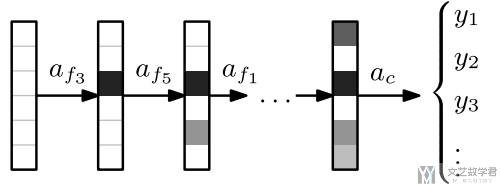
对上图的详细描述, One sample at a tme, we sequentially acquire features, until enough information is gathered and classification is performed.
本文的创新点
- Since 2011, we are not aware of any work improving upon the method of Dulac-Arnold et al. In this paper, we take a fresh look at the method and show that simple replacement of the linear approximation with neural networks can outperform the most recent methods specifically designed for the CwCF problem. (在这个领域, 从Dulac-Arnold之后没有改进, 于是本文对强化学习中线性核使用神经网络进行替代)
- The RL approach has a relatively low number of parameters and is robust with respect to their modification, which facilitates the deployment. (使用RL的方法, 有较少的参数, 且有较好的robust)
- We argue that our method is extensible in various ways and we implement two extensions (本文提出的模型是很容易进行扩展的, 作者实现了两个扩展):
- First we identify parts of the model that can be pre-trained in a fast and supervised way, which improves performance initially during the training. (可以对模型进行预训练)
- Second, we allow the model to selectively use an external High-Performance Classifier (HPC), trained separately with all features. (可以让模型选择使用所有features训练好的High-Performace Classifier (HPC) 模型)
- Lastly, using RL for CwCF enables continual adaptation to changes in non-stationary environments, commonly present in real-world problems.
问题描述
下面我们对上面的问题, 使用符号化来进行描述:
- 现在有一组数据(x,y)从data distribution D中抽样得到. x包含n个features, 记为f1, f2; y是class.
- 有一个函数c, c(f_i)表示第i个特征的cost.
现在有两个函数, 分别是y(x)和z(x). y(x)是预测函数, z(x)是进行特征的挑选. 我们的目标是, The goal is to find such parameters that minimize the expected classification error along with lambda scaled expected feature cost. 具体的函数如下所示, 整个分为两部分, 左侧是希望预测的准确, 右侧是希望选择的特征少, 即features cost比较低:
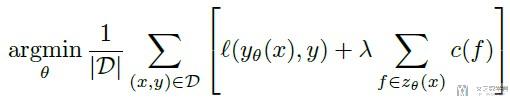
We view the problem as a sequential decision-making problem, where at each step an agent selects a feature to view or makes a class prediction. (解上面最优化的方法, 使用强化学习, 每一步agent就是选一个feature或是进行分类判断)
下面是说明如何将上面问题表示为强化学习. We treat each sample as a separate episode. 首先一个样本就是一个独立的episode.
State的表示如下, 由三个部分组成. (x,y)就是表示一个sample, F表示目前被选中的特征. 这里还需要对着源代码看一下是如何定义observation.

Action包含两部分:
- Ac表示classification action, Ac会结束整个eposide, 分类正确则获得reward=0, 分类错误则获得reward=-1;
- Af表示selecting action. 每次选择一个feature都会获得reward为-c(f).
Reward function如下所示:
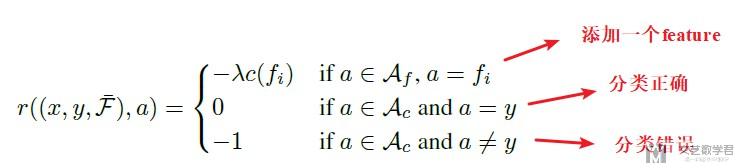
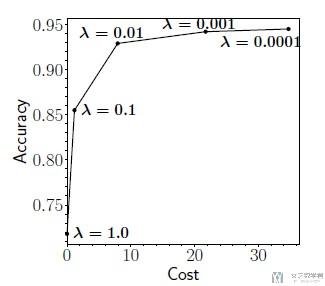
我们可以通过改变lambda的大小, 来调整使得模型是更倾向于准确率, 还是减少特征数量. 变化趋势如下图所示. (Higher lambda forces the agent to prefer lower cost and shorter episodes over precision and vice versa (反之亦然).)
初始状态是不包含任何选中的特征. 状态的更新如下所示:
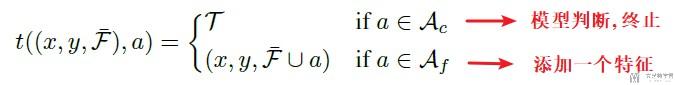
于是找到一个最优的策略, 最大化期望的reward, 就相当于解决了上面的最优化问题, 这个可以参考论文Dulac-Arnold et al. (2011).
整个过程如下所示, 每次选一个feature加入, 得到负的reward, 最后根据所有的features来进行判断.
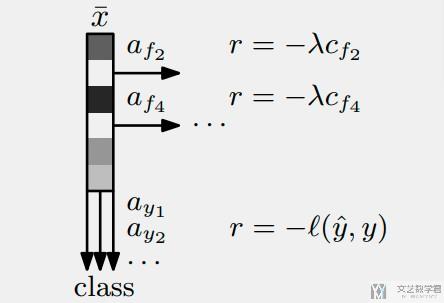
方法的具体描述
使用的模型, We use Q-learning with functon approximaton in various implementatons: linear approximaton, approximaton with neural networks (DQN) and with recent deep RL techniques (double Q learning, dueling architecture and Retrace). (在具体实现的时候, 使用了不同的函数估计的方法来实现Q-Learnig.)
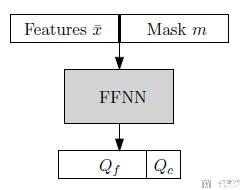
模型的输入, 模型的输入由两部分组成, 分别是:
- A masked vector of the original x (位置的特征是0, 其余特征保留)
- Mask m is a vector denoting whether a specific feature has been acquired, and it contains 1 at a position of acquired features, or 0. (mask也要作为特征输入)
最后会将上面两部分合并作为输入, 这样就可以用来区分特征值是0, 是表示feature is not present还是observe value of zero.
于是模型的整体结构如下图所示:
方法的一些扩展
上面是最基本的模型. 这篇文章有说使用这种方法有很强的扩展性, 这里就介绍了几种扩展的方式.
Pre-training, 因为上面的模型包括最后的分类部分, 即当action是Ac的时候, 整个eposide就结束了. 所以预训练的方法就是, 选出一个sample x, 接着生成一个mask m, m中每个都是服从伯努利分布. 这样有了m和sample x就可以组成训练样本. 我们使用这一部分的数据来预训练部分Q network.
HPC (High-Performance Classifier), 这个扩展相当于是会额外使用一个模型, 这个模型使用全部的特征来进行分类. 同时, 我们会新增一个action, 这个action表示何时使用这个HPC模型. 执行这个action之后一个eposide结束. 使用这个HPC有下面两个意义:
- It improves performance for samples needing a large amount of features.
- It offloads the complex samples to HPC, so the model can focus its capacity more effectively for the rest, improving overall performance. (对一些复杂的样本, 使用HPC来进行分类, 可以使得整个模型专注于整体的表现)
Reward Function, 关于reward function也可以进行自定义设置. 例如对于多分类问题, 可以设置不同的class在分类错误的情况下获得不同的cost.
Feature Grouped, 在显示情况中, 许多特征是一起得到的, 我们可以将这些特征进行打包, 看成一组特征, 共同选中或是不被选中. Several features often come together with one request (e.g. one request to a cloud service can provide many values). In this case, the features can be grouped together to create a macro-feature, which is provided at once.
实验以及实验结果
在本实验中, 我们选用了3种方法:
- Q-learning with linear approximation (RL-lin)
- Q-learning with neural networks (RL-dqn)
- The complete agent with all extensions (RL)
与两种经典的方法, Adapt-Gbrt and BudgetPrune在8个数据集上进行比较. 对于cost的选择, 作者在这里在不同的数据集上测试了两种cost, 分别是:
- 随机从{0.2, 0.4, 0.6, 0.8}中进行选择;
- [0, 1]的均匀分布中进行选择;
作者在这里训练了一个SVM作为external classifier (HPC). 下图是总的实验结果. 有两条水平线, 是SVM和普通的神经网络使用全部特征训练的准确度. (The horizontal lines correspond to the plain neural network based classifier and SVM.)
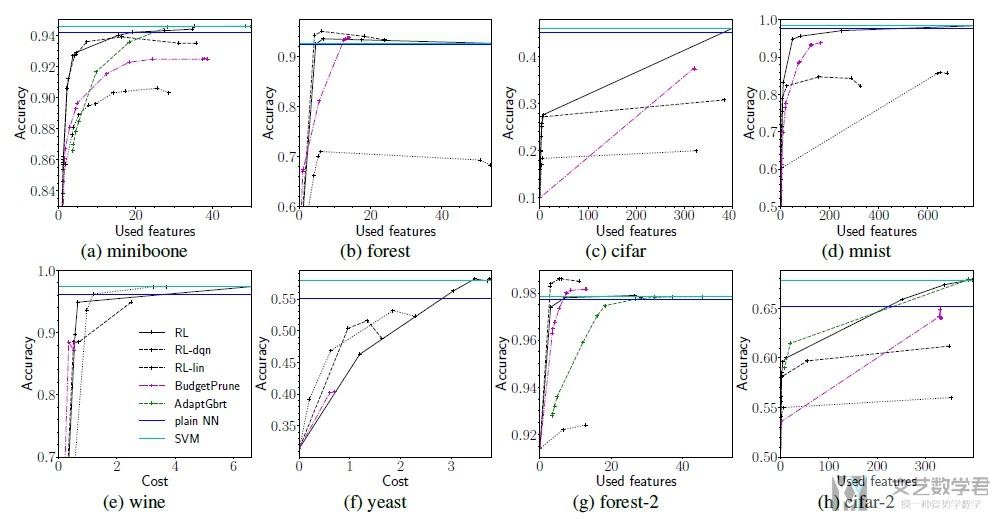
接下来是对实验结果的一些描述. The RL outperforms Adapt-Gbrt and BudgetPrune in miniboone, forest (except for the very low cost range), cifar, mnist and cifar. On cifar-2 and forest-2, there are ranges of costs, where another algorithm is better, but it is a different algorithm each time. Minding the fact that the algorithm was not specifically tuned for each dataset, this indicates high robustness. (在不同的数据集上都有较好的效果, 说明有较好的robustness)
接下来作者还比较了收敛速度的快慢. 直接使用RL-dqn收敛速度是比较慢的. Without advanced RL techniques, RL-dqn converges slowest. With pretraining, the model is initialized closer to an optima.
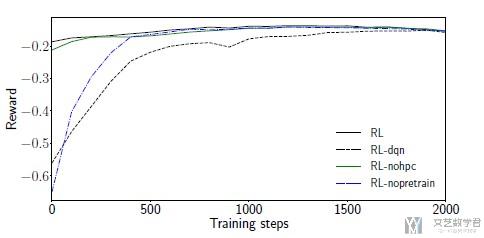
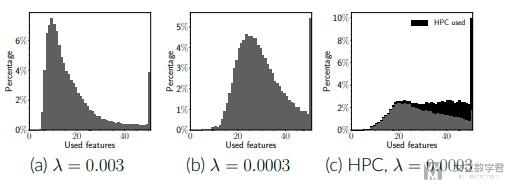
接着作者比较了lambda不同的时候, 使用特征数量的不同. 可以看到lambda越大, 模型会偏向于使用越少的特征来进行判断.
- The agent classifies 40% of all samples with under 15 features and with almost no HPC usage. (一共是40+的特征, 有40%的样本只使用了15个特征进行判断)
- For the rest of samples, the agent queries the HPC in about 19% cases. (有19%的样本使用了HPC的方法)
- The histogram confirms that the agent is classifies adaptively, requesting a different amount of features across samples, and triggering the external classifier on demand.
- With further analysis, we confirm that the agent also requests a different set of features for different samples. (不同的sample使用的feature的个数和特征都是不同的)
Deep reinforcement learning for imbalanced classification
这一篇文章在介绍数据不平衡方法处理(网络加密流量实验-数据不平衡处理 )的时候也介绍过, 在这里再强调一遍.
- Lin, Enlu, Qiong Chen, and Xiaoming Qi. "Deep reinforcement learning for imbalanced classification." Applied Intelligence (2020): 1-15.
问题描述
- Data in real-world application often exhibit skewed class distribution which poses an intense challenge for machine learning. (现实中存在很多数据不平衡的问题)
- Conventional classification algorithms are not effective in case of imbalanced data distribution, and may fail when the data distribution is highly imbalanced. (一些分类算法在面对数据不平衡的时候可能会失效)
本文创新点
To address this issue, we propose a general imbalanced classification model based on deep reinforcement learning, in which we formulate the classification problem as a sequential decision-making process and solve it by a deep Q-learning network. (本文的主要方法是基于Deep Q-Learning来实现的)
下面是本文三个创新点的描述:
- 1) To formulate the classification problem as a sequential decision-making process and propose a deep reinforcement learning framework for imbalanced classification. (将分类问题转换为顺序决策问题, 并提出一个deep q-learning的框架来解决数据不平衡的问题)
- 2) To design and implement the DQN based imbalanced classification model (DQNimb), which mainly includes building the simulation environment, defining the interaction rules between agent and environment, and designing the specific reward function. (设计了一个基于DQN的不平衡的分类问题, 包括环境仿真, 定义主体和环境之间的相关规则, 设计奖励函数)
- 3) To study the performance of our model through experiments and compare it with other methods of imbalanced data learning. (通过实验比较实验的结果, 与其他的处理数据不平衡的方法进行比较)
关于这个方法为什么会对处理数据不平衡的问题的时候是有效的:
Our DQNimb model has the smallest decrease because our algorithm possesses both the advantages of the data level models and the algorithmic level models.
- In the data level, our model DQNimb has an experience replay memory of storing interactive data during the learning process. When the model misclassifies a positive sample, the current episode will be terminated, which can alleviate the skewed distribution of the samples in the experience replay memory. (当对少数样本分类错误的时候, episode会停止, 这样迫使其将更多的属于少数样本分类正确)
- In the algorithmic level, the DQNimb model gives a higher reward or penalty for positive samples, which raises the attention to the samples in the minority class and increases the probabilities of positive samples being correctly identified. (对属于少数样本的类别给出一个更高的reward)
解决数据不平衡的方法
在这里, 使用一个框架, Imbalanced Classification Markov Decision Process (ICMDP) framework 来解决数据不平衡的分类问题. 关于其中的一些值:
- State S: state在这里就是指样本x, 例如进行图像分类, 这里就是图片.
- Action A: action这里是模型的label, 做出预测就是做出action. 在原文中, 0 represents the minority class and 1 represents the majority class.
- Reward R: the absolute reward value of sample in the minority class is higher than that in the majority class. (在少数类的reward是要比多数类的reward要多的)
- Episode: An episode ends when all samples in training data set are classified or when the agent misclassifies a sample from the minority class. (关于一个episode的结束, 是在所有数据都能成功分类之后, 或者错误分类一个少数的样本, 这个是希望可以尽量多的将minority class分类正确, 这里结束的条件要注意)
下面详细说明一下reward function, 对于minority class和major class的不同设定.
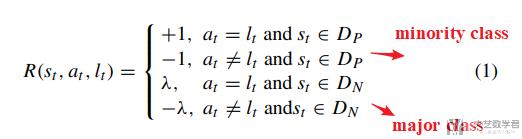
其中λ的取值是在[0,1]之间, 也就是会小于等于1, 也就是major class的reward会小. (Assume the reward value be 1 or −1 when the agent correctly or incorrectly classifies a minority class sample, be λ or −λ when the agent correctly or incorrectly classifies a majority class sample.)
关于λ的取值, 在本论文中取值为Num(D_p)/Num(D_n), 也就是少数类样本的个数/多数类样本的个数.
关于λ的取值, 为什么是Num(D_p)/Num(D_n), 可以有下面的一些解释. 首先整个模型的loss function如下所示:
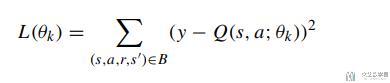
其中y是他的实际值, 也就是一步预测的值.
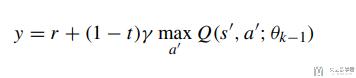
接着我们对上面的loss function进行求导, 结果如下:
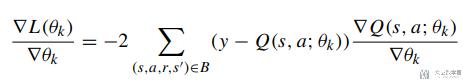
在这里因为是二分类问题, 所以y由两个部分组成, 分别是majority class和minority class, 他们获得的reward是不一样的, 所以上面的y可以拆分为下面两个式子: 其中11是minority class, 12是majority class (式子12中会乘λ).
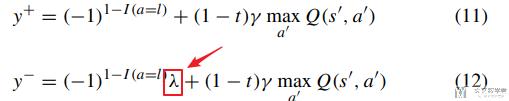
将式子11和式子12代入上面求导的式子中, 得到下面的式子13, 这个有三个部分组成: 第一部分是两类在一起的, 2和3部分分别对应majority class和minority class. 第三部分含有λ.
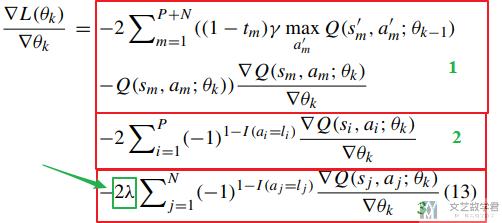
第2和第3部分的差异在于, 求和的数量不同, 如果从majority中进行取值, N的值会大于P的值, 所以需要乘λ=P/N来使得第2部分和第3部分的值相似, 来解决数据不平衡的问题.
于是, 整个算法的流程如下所示:

其中上面返回reward和terminal的算法如下所示:

本文的实验
这里作者主要进行了三大类的实验:
- 验证方法的有效性, 分类结果会比其他的处理数据不平衡的方法要好;
- 验证随着数据不平衡性的提高, 模型的准确率下降较低;
- 验证关于reward function中λ的取值;
为了验证本文方法的有效性, 作者将这一种方法与其他7种处理数据不平衡的方法进行比较, 同时在6个数据集上进行测试. 部分实验结果如下图所示:
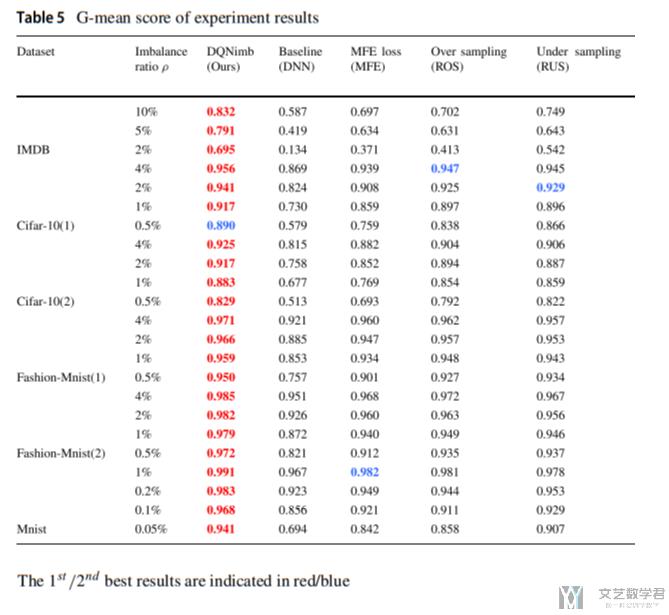
作者首先比较了数据平衡时, 模型也是有效的. 接着在数据不平衡的时候再次进行实验, 强调提出的方法的有用. (The results of data sampling methods, costsensitive learning methods, threshold adjustment method and deep imbalanced learning methods are much better than DNN model in imbalanced classification problems, however, our model DQNimb achieves an outstanding performance with an overwhelming superiority. In the IMDB text dataset, the G-mean scores of our method DQNimb are normally 5% higher than the second-ranked method CRL and significantly better than that of other methods.)
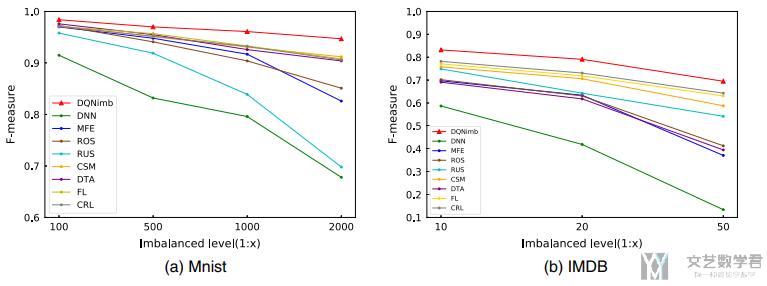
接着作者进行了另外一个实验, 增加数据的imbalance level, 来查看准确率的变化. 可以看到其他的方法都有较大程度的下降, 自己的方法准确率下降较低.
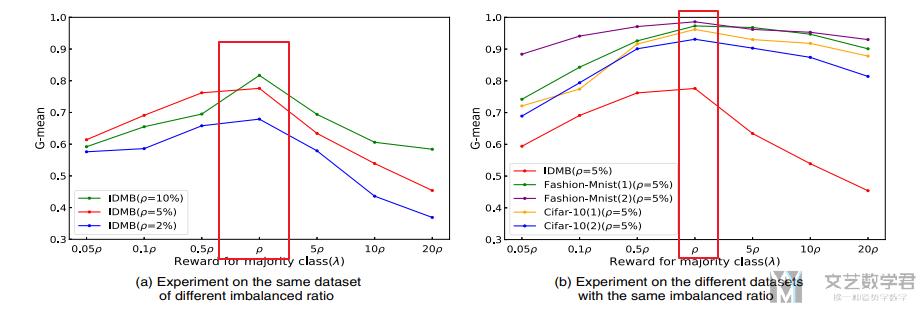
最后作者比较了λ取值不同时, 对最后结果的影响, 最后表示λ=ρ=Num(minority class)/Num(majority class)的时候, :
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论