文章目录(Table of Contents)
简介
这一部分会总的介绍一下模型的可解释性。这一篇会是模型的可解释性的一个总结。对于每一种方法的具体细节,我会单独有文章进行叙述,会在这里给出一些模型可解释性方法的介绍。
下面把一些参考资料的链接罗列在这里,把参考链接放在最上面。
参考资料
- 模型解释的数据(这是一本电子书, 内容很全, 讲得由浅入深, 讲得很具体) : Interpretable Machine Learning
- 为什么需要模型的解释 : Interpreting machine learning models
- 技术总结型文章(里面解释了常见得模型解释得方法) : Hands-on Machine Learning Model Interpretation
- 技术总结型文章(常见技术得总结) : Model Interpretation Strategies
- Pytorch实现CNN的模型解释 : Pytorch implementation of convolutional neural network visualization techniques
- LIME技术框架 : Github-LIME
一些具体的模型解释方法
这里是一些对于深度模型解释的方法介绍, 这一部分我在后面也是有详细的介绍.
- Saliency Maps : Saliency Maps的原理与简单实现(使用Pytorch实现)
- LIME(So instead of trying to understand the entire model at the same time, a specific input instance is modified and the impact on the predictions are monitored.)(从局部进行解释), 模型解释-LIME的原理和实现
- 使用LIME来解释Pytorch生成的模型, Pytorch例子演示及LIME使用例子
- Shapley Value, 模型解释–Shapley Values
- SHapley Additive exPlantions (SHAP), 模型解释–SHAP Value的简单介绍
为什么需要模型可解释性
这一部分的参考链接为(包括这一部分的图片来源) : Interpreting machine learning models
为什么需要解释模型呢,我觉得下面这张图真的是很形象。
更好的帮助决策
As correlation often does not equal causality, a solid model understanding is needed when it comes to making decisions and explaining them.(在进行决策的时候, 我们希望知道模型的细节来进行决策, 帮助决策)
Model interpretability is necessary to verify the that what the model is doing is in line with what you expect .(模型的解释可以验证模型的工作是否符合我们的期望)
Users need to understand and trust the decisions made by machine learning models, especially in sensitive fields such as medicine.(某些领域, 需要知道模型的判断依据, 如医药类的领域)
In industries like finance and healthcare it is essential to audit the decision process and ensure it is e.g. not discriminatory or violating any laws. With the rise of data and privacy protection regulation like GDPR, interpretability becomes even more essential. In addition, in medical applications or self-driving cars, a single incorrect prediction can have a significant impact and being able to ‘verify’ the model is critical. Therefore the system should be able to explain how it reached a given recommendation.(伦理和法律原因, 决策过程需要进行审计, 确保没有歧视或是违反法律, 同时对于自动驾驶和医疗每一步都有重大影响的, 人们需要知道机器给出这个建议的原因)
帮助模型选择与优化
It allows you to verify hypotheses and whether the model is overfitting to noise.(可以帮助我们更好的优化模型, 帮助模型的选择与优化)
It is easier to compare two candidate models for the task or to switch models if they are from different types.(当有多个模型选择的时候, 模型的解释是一个判断的标准)
When building a text classifier you can plot the most important features and verify whether the model is overfitting on noise. If the most important words do not correspond to your intuition (e.g. names or stopwords), it probably means that the model is fitting to noise in the dataset and it won’t perform well on new data.(如在文本分类问题我们查看重要词是否符合我们的直觉, 模型是否是fit了一些noise, 从而导致在new data上效果不好)
模型解释的方法
Feature importance is a basic (and often free) approach to interpreting your model. (通常情况下我们会使用feature importance来进行模型的解释)
Generalised Linear Models(GLM)
Most common applications for GLM's are regression (linear regression), classification (logistic regression) or modelling Poisson processes (Poisson regression). The weights that are obtained after training are a direct proxy of feature importance and they provide very concrete interpretation of the model internals.(我们可以使用线性模型的权重来解释特征的重要性)
e.g. when building a text classifier you can plot the most important features and verify whether the model is overfitting on noise. If the most important words do not correspond to your intuition (e.g. names or stopwords), it probably means that the model is fitting to noise in the dataset and it won't perform well on new data.(这个例子是我们可以通过权重来获得积极词汇和消极词汇)
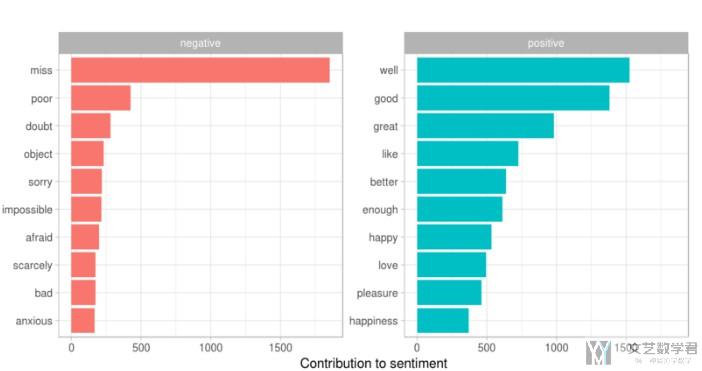
Random forest and SVM’s
In Random Forest, feature importance comes for free when training a model, so it is a great way to verify initial hypotheses and identify 'what' the model is learning.
The weights in kernel based approaches such as SVM's are often not a very good proxy of feature importance. The advantage of kernel methods is that you are able to capture non-linear relations between variables by projecting the features into kernel space. On the other hand, just looking at the weights as feature importance does not do justice to the feature interaction.(SVM如果使用核函数则kernel weight不能完全解释feature importance)
E.g. By looking at the feature importance, you can identify what the model is learning. As a lot of importance in this model is put into time of the day, it might be worthwhile to incorporate additional time-based features.(下面举一个使用random forest来解释特征的重要度)
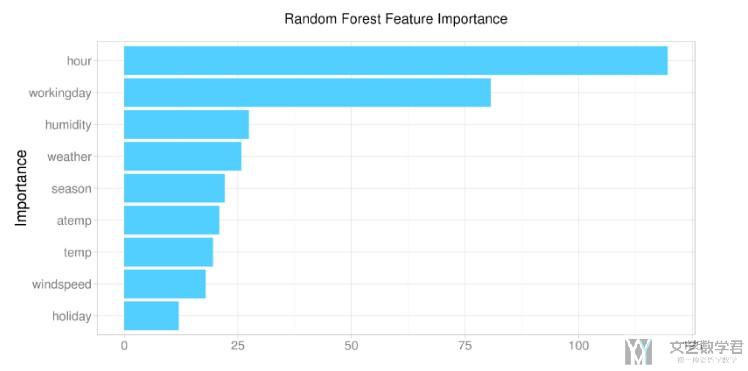
Deep Learning
In gradient-based methods, the gradients of the target concept calculated in a backward pass are used to produce a map that highlights the important regions in the input for predicting the target concept. This is typically applied in the context of computer vision.(后面讲的Saliency Maps就是一种gradient-based的方法)

Attention-based methods are typically used with sequential data (e.g. text data). In addition to the normal weights of the network, attention weights are trained that act as 'input gates'. These attention weights determine how much each of the different elements in the final network output. Besides interpretability, attention within the context of the e.g. text-based question-answering also leads to better results as the network is able to 'focus' its attention.
In question answering with attention, it is possible to indicate which words in the text are most important to determine the answer on a question.

具体的方法
这里列一下后面会用到的具体的方法, 详细的方法介绍查看每个方法的链接.
- Saliency Maps : Saliency Maps的原理与简单实现(使用Pytorch实现)
- LIME(So instead of trying to understand the entire model at the same time, a specific input instance is modified and the impact on the predictions are monitored.)(从局部进行解释), 模型解释-LIME的原理和实现
- 使用LIME来解释Pytorch生成的模型, Pytorch例子演示及LIME使用例子
- Shapley Value, 模型解释–Shapley Values
- SHapley Additive exPlantions (SHAP), 模型解释–SHAP Value的简单介绍
- 微信公众号
- 关注微信公众号
-

- QQ群
- 我们的QQ群号
-












评论